评价方法 (scoring)
CA
-
Orange.evaluation.CA(results=None, **kwargs)[source]
一个 sklearn.metrics.classification.accuracy_score 的装饰器。以下是它的文档:准确度分类分数。
在多标签分类中,此函数计算子集精度:为样本预测的标签集必须与y_true中的相应标签集精确匹配。
请阅读《用户手册》中的更多内容。
Precision
-
Orange.evaluation.Precision(results=None, **kwargs)[source]
sklearn.metrics._classification.precision_score 的包装器。 以下是它的文档:
计算精度。
精度是
tp / (tp + fp)的比值,其中tp是真阳性数,fp是假阳性数。 精度直观地是分类器不将负样本标记为正样本的能力。最佳值为 1,最差值为 0。
请阅读《用户手册》中的更多内容。
Recall
-
Orange.evaluation.Recall(results=None, **kwargs)[source]
sklearn.metrics._classification.recall_score 的包装器。 以下是它的文档:
计算召回率。
召回率是
tp / (tp + fn)的比率,其中tp是真阳性数,fn是假阴性数。 召回率直观地是分类器找到所有正样本的能力。最佳值为 1,最差值为 0。
在用户指南中信息。
F1
-
Orange.evaluation.F1(results=None, **kwargs)[source]
sklearn.metrics._classification.f1_score 的包装器。 以下是它的文档:
计算 F1 分数,也称为平衡 F 分数或 F 度量。
F1 分数可以解释为准确率和召回率的调和平均值,其中 F1 分数在 1 时达到其最佳值,在 0 时达到最差分数。准确率和召回率对 F1 分数的相对贡献是相等的。 F1分数的公式是:
python">F1 = 2 * (precision * recall) / (precision + recall)在多类和多标签的情况下,这是每个类的 F1 分数的平均值,权重取决于平均参数。
在用户指南中信息。
PrecisionRecallFSupport
-
Orange.evaluation.PrecisionRecallFSupport(results=None, **kwargs)[source]
sklearn.metrics._classification.precision_recall_fscore_support 的包装器。以下是它的文档:
计算每个类的精度、召回率、F-measure 和支持。
精度是比率
tp / (tp + fp),其中tp是真阳性数,fp是假阳性数。精度直观地是分类器不将负样本标记为正样本的能力。召回率是
tp / (tp + fn)的比率,其中tp是真阳性数,fn是假阴性数。召回率直观地是分类器找到所有正样本的能力。F-beta 分数可以解释为准确率和召回率的加权调和平均值,其中 F-beta 分数在 1 处达到其最佳值,在 0 处达到最差分数。
F-beta 分数权重的召回率比准确率高 1 倍。 beta == 1.0 意味着召回率和精度同样重要。
支持度是 y_true 中每个类的出现次数。
如果
pos_label为None并且在二进制分类中,如果平均值是“micro”、“macro”、“weighted”或“samples”之一,则此函数返回平均精度、召回率和 F-measure。在用户指南中信息。
AUC
-
Orange.evaluation.AUC(results=None, **kwargs)[source]
${sklpar}
参数
results (Orange.evaluation.Results) – 模型测试中存储的预测和实际数据。 target (int, optional (default=None)) -- 要报告的类的值。
Log Loss
-
Orange.evaluation.LogLoss(results=None, **kwargs)[source]
${sklpar}
参数
results (Orange.evaluation.Results) – 模型测试中存储的预测和实际数据。 eps (float) – p=0 或 p=1 的对数损失未定义,因此概率被限制为 max(eps, min(1 - eps, p))。 normalize (bool, optional (default=True)) – 如果为真,则返回每个样本的平均损失。 否则,返回每个样本损失的总和。 sample_weight (array-like of shape = [n_samples], optional) – 样本权重。
举例
Orange.evaluation.LogLoss(results)
array([ 0.3...])
MSE
-
Orange.evaluation.MSE(results=None, **kwargs)[source]
sklearn.metrics._regression.mean_squared_error 的包装器。 以下是它的文档:
均方误差回归损失。
在用户指南中信息。
MAE
-
Orange.evaluation.MAE(results=None, **kwargs)[source]
sklearn.metrics._regression.mean_absolute_error 的包装器。 以下是它的文档:
平均绝对误差回归损失。
在用户指南中信息。
R2
-
Orange.evaluation.R2(results=None, **kwargs)[source]
sklearn.metrics._regression.r2_score 的包装器。 以下是它的文档:
R 2 R^2 R2(确定系数)回归评分函数。
最好的分数是 1.0,它可以是负数(因为模型可以任意变坏)。 一个始终预测 y 的期望值的常量模型,不考虑输入特征, R 2 R^2 R2将得到0.0 分。
在用户指南中信息。
CD diagram
-
Orange.evaluation.compute_CD(avranks, n, alpha=‘0.05’, test=‘nemenyi’)[source]
根据给定的 alpha(alpha=”0.05” 或 alpha=”0.1”)返回 Nemenyi 或 Bonferroni-Dunn 测试的关键差异,用于平均排名和测试数据集 N 的数量。测试可以是 Nemenyi 两尾的“nemenyi” 测试或“bonferroni-dunn”用于 Bonferroni-Dunn 测试。
-
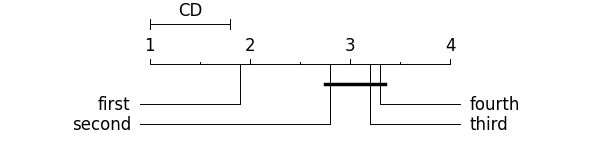
Orange.evaluation.graph_ranks(avranks, names, cd=None, cdmethod=None, lowv=None, highv=None, width=6, textspace=1, reverse=False, filename=None, **kwargs)[source]
绘制 CD 图,用于显示方法性能的差异。 参见 “Janez Demsar,多个数据集上分类器的统计比较,2006 年 7 月(1 月):1-30”。
需要 matplotlib 才能工作。
图像绘制在使用 import matplotlib.pyplot as plt 导入的 plt 上。
参数
python">avranks(浮动列表)– 方法的平均排名。 names (list of str) -- 方法的名称。 cd (float) - 用于方法之间差异的统计显着性的关键差异。 cdmethod (int, optional) – 与其他方法比较的方法如果省略,则显示方法的成对比较 lowv (int, optional) – 显示的最低等级 highv (int, optional) – 显示的最高等级 width (int, optional) – 默认宽度(以英寸为单位)(默认值:6) textspace (int, optional) – 方法名称的图形边上的空间(以英寸为单位)(默认值:1) reverse (bool, optional) – 如果设置为 True,则最低排名在右侧(默认值:False) filename (str, optional) – 输出文件名(带扩展名)。 如果没有给出,该函数不会写入文件。Example
import Orange
import matplotlib.pyplot as plt
names = ["first", "third", "second", "fourth" ]
avranks = [1.9, 3.2, 2.8, 3.3 ]
cd = Orange.evaluation.compute_CD(avranks, 30) #tested on 30 datasets
Orange.evaluation.graph_ranks(avranks, names, cd=cd, width=6, textspace=1.5)
plt.show()
该代码生成以下图表:
reference
@online{BibEntry2022Jan,
title = {{Scoring methods (scoring) — Orange Data Mining Library 3 documentation}},
year = {2022},
month = {1},
date = {2022-01-08},
urldate = {2022-01-16},
language = {english},
hyphenation = {english},
note = {[Online; accessed 16. Jan. 2022]},
url = {https://orange3.readthedocs.io/projects/orange-data-mining-library/en/latest/reference/evaluation.cd.html}
}



