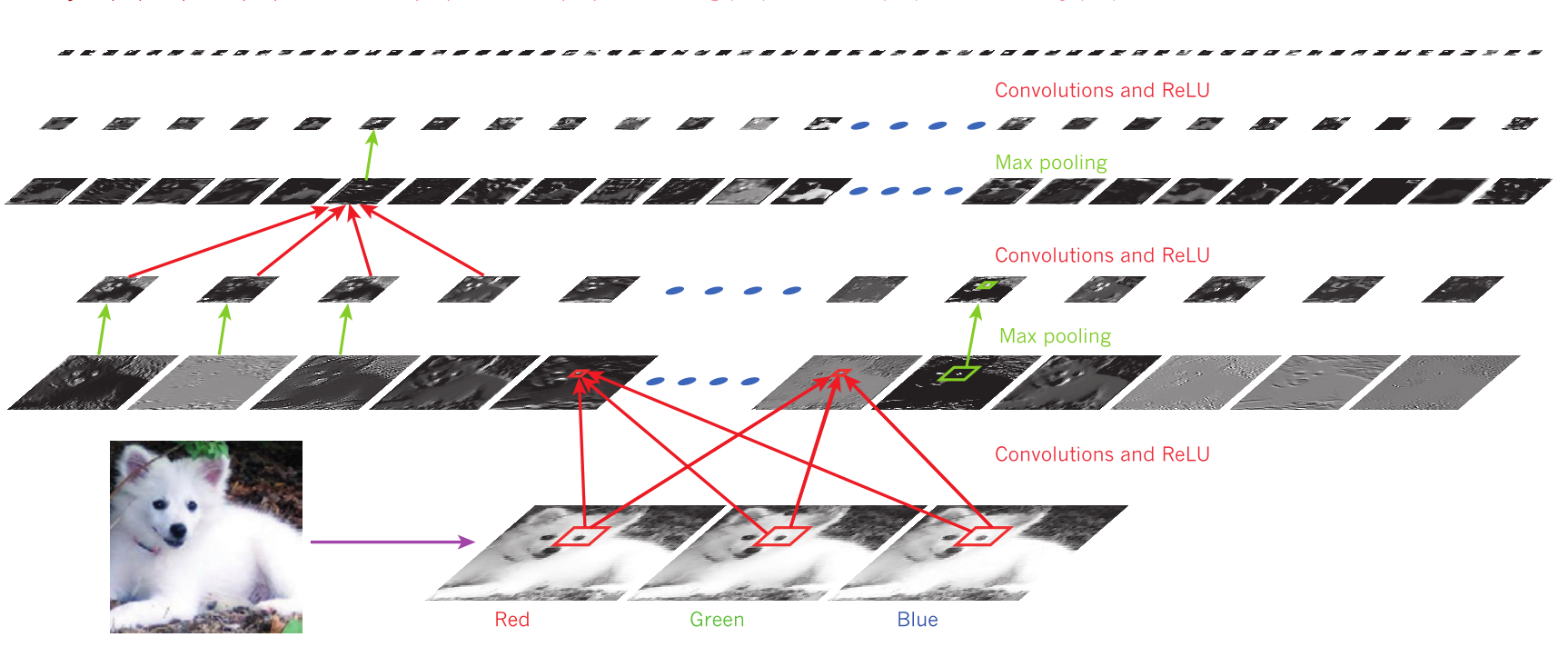
sklearnTransformerestimator_0">sklearn——转换器(Transformer)与预估器(estimator)
文章目录
- sklearn——转换器(Transformer)与预估器(estimator)
- 转换器 Transformer
- fit 与 fit_transform 与 transform
- 值得注意的是
- 扒拉了下源码(这里可以跳过,看上面结论就够了)
- 预估器 Estimator
在我之前接触的sklearn中,有 SimpleImputer 、OrdinalEncoder、OneHotEncoder,他们的共同点是都用于对数据特征预处理。
在对他们的使用中都无法避免遇到:fit_transform、transform。初时,还没有充分了解的我只是记住了这一特征,最后了解到 sklearn 中 Transformer和 estimator的概念,认为有必要整合一下。
转换器 Transformer
由于在进行模型fit之前,需要先对数据集进行预处理,这里包括对空值的处理、对object变量的预处理。
可以看作需要对数据集进行一个转换,则这个时候就需要用上Transformer了,本质上SimpleImputer 、OrdinalEncoder、OneHotEncoder 都属于 Transformer。
例如,原数据 X_train 经过一个SimpleImputer 后,得到了经过空值插补的新数据集 X_train_new。
fit 与 fit_transform 与 transform
以 SimpleImputer 为例,若需要均值插补,那么在插补之前首先需要知道空值对应列的均值是多少。
故 fit 是先计算矩阵空值(缺失值)对应列的相关值大小,如均值、中位数、频率最高的数。
transform 则在根据fit 计算的值对输入的数据集进行变换。
故,在对一个新的数据集处理之前,需要先fit 一次,得到相关值,在transform 进行转换。但一般情况下,我们会直接使用 fit_transform 。
fit_transform 内部是先对数据集进行 fit,在顺势对其调用transform。
>>>import numpy as np
>>>from sklearn.impute import SimpleImputer
>>>imp = SimpleImputer(missing_values=np.nan, strategy='mean')
>>>imp.fit([[1, 8], [np.nan, 4], [7, 6]])
SimpleImputer()
>>>X
array([[nan, 2.],
[ 6., nan],
[ 7., nan]])
>>>print(imp.transform(X))
[[4. 2.]
[6. 6.]
[7. 6.]]
>>> print(imp.fit_transform(X))
[[6.5 2. ]
[6. 2. ]
[7. 2. ]]
第10行是根据提前输入的数据进行fit, 再根据fit 保存的均值,来对X进行 transform。输入的数组第一列平均值为 (1 + 7)/2 = 4 ,第二列的均值是 (8 + 4 + 6)/3 = 6,即除数是非空值的个数。 得到均值后再直接插入X的空值部分,不考虑 X 的数据。
第14行,对 X 直接进行fit_transform 即对X 先 fit ,再对X 进行 transform ,道理同上。
值得注意的是
在对数据集中, 训练集和验证机进行转换的时候,只需要对训练集调用fit即可,对于验证机直接调用transform(),因为为数据集的一致性,对验证集的转换最好同训练集一致。 (例如对训练集进行OrdinalEncoder 编码, 若对验证机也调用 fit_transform,很有可能训练集验证集中,对于同一个 object值的编码不同,比如对训练集中的球的颜色红色编码为 3 ,验证集中却对其编码为 6)
扒拉了下源码(这里可以跳过,看上面结论就够了)
翻了下源码,SimpleImputer 、OrdinalEncoder、OneHotEncoder都有基类class _BaseEncoder(TransformerMixin, BaseEstimator) ,虽然它也有基类TransformerMixin,但是这个代码我没看大明白, 只能看出return self.fit(X, **fit_params).transform(X), 先 fit 了一次,再直接调用了一次 transform。
所以简单来说 fit_transform 即 先调用了一次 fit 再调用了一次 transform。
class TransformerMixin:
"""Mixin class for all transformers in scikit-learn."""
def fit_transform(self, X, y=None, **fit_params):
"""
Fit to data, then transform it.
拟合数据并转换它
Fits transformer to `X` and `y` with optional parameters `fit_params`
and returns a transformed version of `X`.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Input samples.
y : array-like of shape (n_samples,) or (n_samples, n_outputs), \
default=None
Target values (None for unsupervised transformations).
**fit_params : dict
Additional fit parameters.
Returns
-------
X_new : ndarray array of shape (n_samples, n_features_new)
Transformed array.
"""
# non-optimized default implementation; override when a better
# method is possible for a given clustering algorithm
if y is None:
# fit method of arity 1 (unsupervised transformation)
return self.fit(X, **fit_params).transform(X)
else:
# fit method of arity 2 (supervised transformation)
return self.fit(X, y, **fit_params).transform(X)
以OneHotEncoder 为例,直接看它的,fit 和 transform, 会发现他们都调用了基类_BaseEncoder的 _fit() 和 transform()。
def _fit(self, X, handle_unknown="error", force_all_finite=True):
self._check_n_features(X, reset=True)
self._check_feature_names(X, reset=True)
X_list, n_samples, n_features = self._check_X(
X, force_all_finite=force_all_finite
)
self.n_features_in_ = n_features
if self.categories != "auto":
if len(self.categories) != n_features:
raise ValueError(
"Shape mismatch: if categories is an array,"
" it has to be of shape (n_features,)."
)
self.categories_ = []
for i in range(n_features):
Xi = X_list[i]
if self.categories == "auto":
cats = _unique(Xi)
else:
cats = np.array(self.categories[i], dtype=Xi.dtype)
if Xi.dtype.kind not in "OUS":
sorted_cats = np.sort(cats)
error_msg = (
"Unsorted categories are not supported for numerical categories"
)
# if there are nans, nan should be the last element
stop_idx = -1 if np.isnan(sorted_cats[-1]) else None
if np.any(sorted_cats[:stop_idx] != cats[:stop_idx]) or (
np.isnan(sorted_cats[-1]) and not np.isnan(sorted_cats[-1])
):
raise ValueError(error_msg)
if handle_unknown == "error":
diff = _check_unknown(Xi, cats)
if diff:
msg = (
"Found unknown categories {0} in column {1}"
" during fit".format(diff, i)
)
raise ValueError(msg)
self.categories_.append(cats)
def _transform(
self, X, handle_unknown="error", force_all_finite=True, warn_on_unknown=False
):
self._check_feature_names(X, reset=False)
self._check_n_features(X, reset=False)
X_list, n_samples, n_features = self._check_X(
X, force_all_finite=force_all_finite
)
X_int = np.zeros((n_samples, n_features), dtype=int)
X_mask = np.ones((n_samples, n_features), dtype=bool)
columns_with_unknown = []
for i in range(n_features):
Xi = X_list[i]
diff, valid_mask = _check_unknown(Xi, self.categories_[i], return_mask=True)
if not np.all(valid_mask):
if handle_unknown == "error":
msg = (
"Found unknown categories {0} in column {1}"
" during transform".format(diff, i)
)
raise ValueError(msg)
else:
if warn_on_unknown:
columns_with_unknown.append(i)
# Set the problematic rows to an acceptable value and
# continue `The rows are marked `X_mask` and will be
# removed later.
X_mask[:, i] = valid_mask
# cast Xi into the largest string type necessary
# to handle different lengths of numpy strings
if (
self.categories_[i].dtype.kind in ("U", "S")
and self.categories_[i].itemsize > Xi.itemsize
):
Xi = Xi.astype(self.categories_[i].dtype)
elif self.categories_[i].dtype.kind == "O" and Xi.dtype.kind == "U":
# categories are objects and Xi are numpy strings.
# Cast Xi to an object dtype to prevent truncation
# when setting invalid values.
Xi = Xi.astype("O")
else:
Xi = Xi.copy()
Xi[~valid_mask] = self.categories_[i][0]
# We use check_unknown=False, since _check_unknown was
# already called above.
X_int[:, i] = _encode(Xi, uniques=self.categories_[i], check_unknown=False)
if columns_with_unknown:
warnings.warn(
"Found unknown categories in columns "
f"{columns_with_unknown} during transform. These "
"unknown categories will be encoded as all zeros",
UserWarning,
)
大致读了以下,说实话没有看太明白,但是很容易看出,_fit 和 _transform 在主要的循环部分都多次用到,self.categories_ 这个变量,而这个变量来自于sef._fit() 。 即transform 会直接使用 fit 中存储好的预设值。
预估器 Estimator
即 sklearn 中带有的各种算法模型。无论分类器或者回归都属于此类。
常见基础的如决策树、随机森林。
# 决策树
from sklearn.tree import DecisionTreeRegressor // 用于回归问题
from sklearn.tree import DecisionTreeClassifier // 用于分类问题
# 随机胜率
from sklearn.ensemble import RandomForestRegressor
# XGBoost
from xgboost import XGBRegressor
这些预估器在使用上大同小异,以决策树为例。
- 先实例化一个 esitimator
- 再对他进行 fit 拟合,注意这里的 fit 是 esitimator 自带的 fit。
- 再调用 predict 进行预测、预估。
from sklearn.tree import DecisionTreeRegressor // 用于回归问题
from sklearn.tree import DecisionTreeClassifier // 用于分类问题
melbourne_model = DecisionTreeRegressor(random_state = 1)
#Fit model
melbourne_model.fit(X,y)
melbourne_model.predict(X.head()) // 进行模型预测
各模型的比较和详细解释不在这里赘述。
谨记,ML的基础永远是数学基础。