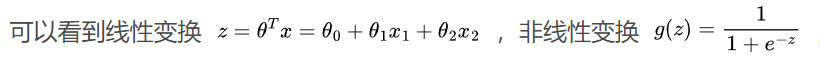人工智能基础总目录
一、介绍
决策树是一种逻辑简单的机器学习算法,采用树形结构,在分类问题中,使 用层层推理来实现最终的分类。一般,一棵决策树包含一个根节点,若干个内 部节点(非叶子节点)和若干个叶子节点,如下图的a,b,c节点。
- 根节点:第一个选择点(对决策结果影响最重要的特征)
- 内部节点(非叶子节点):中间决策过程
- 叶子节点:最终的决策结果

- 什么是特征呢: 特征通常指对结果影响比较大的变量。比如这里的是否饿
决策树分类的两个步骤
决策树通过不断选择最优特征划分数据集,对划分后的子数据集不断迭代,从 而选择最优特征划分,直到所有的数据集属于同一类别,或者没有特征可以选择为 止。选择最优特征的算法有很多种,今天就给大家讲一种最经典的ID3(lterative Dichotomozer 3)决策树算法,其用信息增益选择最优特征。
二、决策树的主要优点
生成一颗决策树是从数据中生成分类模型的一个非常有效的方法,相对于其它分类方法,决策树算法应用最为广泛,其独特的优点包括:
・学习过程中使用者不需要了解很多背景知识,只要训练事例能够用特征–结论 的方式表达出来,就能用该算法进行学习;
・与神经网络等分类算法相比,决策树的训练时间相对较少;
・可解释性强,便于修改,可图形化查看分支结构
缺点
- 不能识别指标间的关联关系,只是进行了判断,维度都是一次的。
三、 信息增益
有两种主要的信息增益算法,公式及代码实现如下:
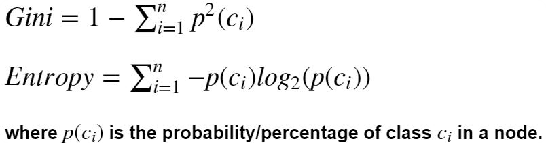
from collections import Counter
import numpy as np
def get_pros(elements):
counter = Counter(elements)
pr = np.array([counter[c] / len(elements) for c in counter])
return pr
def entropy(elements):
pr = get_pros(elements)
return -np.sum(pr * np.log2(pr))
def gini(elements):
pr = get_pros(elements)
return 1 - np.sum(pr**2)
entropy([0, 0, 1, 1, 1,1 ,1, 1]))
gini([0, 0, 1, 1, 1,1 ,1, 1])
1 Entropy 熵
信息增益的公式为:信息增益=信息熵-条件熵。
香农提出:一条信息的信息量大小和它的不确定性有直接的关系。

举个例子:一朵百合开花或不开花是一个随机事件,用随机变量X表示。现 有一些样本x={开,开,开,不开,不开}。
每个事件发生的概率有:p(x=‘开’)=3/5; p(X=‘不开’)=2/5,那么X的熵
H(X)=-(3/5)log(3/5)-(2/5)log(2/5)
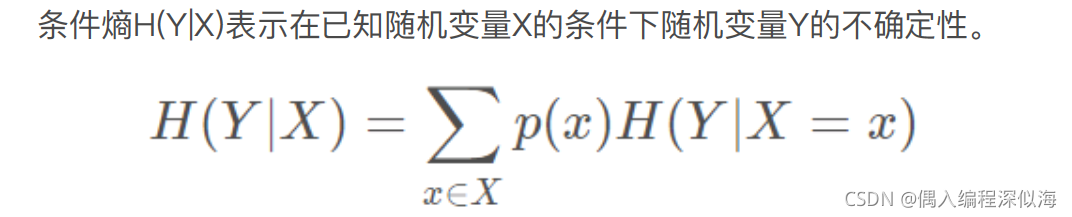
依旧利用百合花的例子了解条件炳。
假设现在使用百合是否开花来预测天气是晴朗的还是有雨的。所以 引入天气变量(Y):晴、雨。
晴天的概率表示为:p(晴)=3/5,
雨天的概率表示 为:p(雨)=2/5。
| 晴:开、开、不开 | 雨:开、不开 |
|---|
现在我们就有了在百合是否开花(X)的条件,天气是晴朗的还是有雨的(Y) 概率分布。所以 H(Y|X) = 3/5[-(2/3)log(2/3)-(1/3)log(1/3)]+2/5[-(1/2)log(1/2)- (1/2)log(1/2)]
3.3 Loss 函数
分类使Loss 函数 最小:
左侧分类个数 / (总个数 * 左边的gini 或 entropy) + 右侧分类个数 / (总个数 * 右边的gini 或 entropy)
Loss = (m_left)/m * G_left + m_right / m * G_right
代码查看不同类别下的gini数据,哪个类别的gini 值最小,然后去掉该特征再继续构建树。
from sklearn.datasets import load_iris
from icecream import ic
from collections import Counter
import numpy as np
import pandas as pd
def get_pros(elements):
counter = Counter(elements)
pr = np.array([counter[c] / len(elements) for c in counter])
return pr
def entropy(elements):
pr = get_pros(elements)
return -np.sum(pr * np.log2(pr))
def gini(elements):
pr = get_pros(elements)
return 1 - np.sum(pr**2)
def cart_loss(left, right, pure_fn):
m_left, m_right = len(left), len(right)
m = m_left + m_right
return m_left / m * pure_fn(left) + m_right / m * pure_fn(right)
sales = {
'gender': ['Female', 'Female', 'Female', 'Female', 'Male', 'Male', 'Male'],
'income': ['H', 'M', 'H', 'M', 'H', 'H', 'L'],
'family-number': [1, 1, 2, 1, 1, 1, 2],
'bought': [1, 1, 1, 0, 0, 0, 1]
}
sales_dataset = pd.DataFrame.from_dict(sales)
target = 'bought'
def find_best_split(training_dataset, target):
dataset = training_dataset
fields = set(dataset.columns.tolist()) - {target}
print(fields)
mini_loss = float('inf')
best_feature, best_split = None, None
for x in fields:
filed_value = dataset[x]
for v in filed_value:
split_left = dataset[dataset[x] == v][target].tolist()
split_right = dataset[dataset[x] != v][target].tolist()
loss = cart_loss(split_left, split_right, pure_fn=gini)
ic(x, v, cart_loss(split_left, split_right, pure_fn=gini))
if loss < mini_loss:
best_feature, best_split = x, v
return best_feature, best_split
if __name__ == '__main__':
ic(find_best_split(sales_dataset, target='bought'))
算法流程
ID3算法采用分治策略,在决策树各级结点上选择属性时,用信息增益作为属性的选择标准,以便在每一个非叶节点进行测试时,能获得关于测试记录最大的类别信息。
具体方法是:检测所有的属性,选择信息增益最大的属性产生决策树结点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树结点的分支,直到所有子集仅包含同一类别的数据为止。最后得到一颗决策树, 它可以对新的样本进行分类。
算法优缺点
- ID3算法的优点是:算法的理论清晰,方法简单,学习能力较强,分类速度快,适合于大规模数据的处理。
- 主要缺点有:ID3算法只能处理离散性的属性;信息增益度量存在一个内在偏置,在计算时会偏袒具有较多取值的属性,但有时取值较多的属性不一定是最优的。ID3算法是非递增学习算法,抗噪性能差,训练例子中正例和反例较难控制。
四、 如何对决策树进行剪枝?
一颗完全生长的决策树所对应的每个叶节点中只会包含一个样本,那么这样就会面临一个很严重的问题,即过拟合。用该决策树进行预测时,在测试集上的效果将会很差。因此需要对决策树进行剪枝,剪掉一些树枝,提升模型的泛化能力。
预剪枝(pre-pruning)和后剪枝(post- pruning)
1 预剪枝
决策树的剪枝通常有两种方法,预剪枝(pre-pruning)和后剪枝(post- pruning)。预剪枝,即在生成决策树的过程中提前停止树的增长。而后剪枝,是在已生成的过拟合决策树上进行剪枝,得到简化版的剪枝决策树。
预剪枝的核心思想是在树中结点进行扩展之前,先计算当前的划分是否能带来模型泛化能力的提升,如果不能,则不再继续生长子树。此时可能存在不同类别 的样本同时存于结点中,按照多数投票的原则判断该结点所属类别。预剪枝对于何时停止决策树的生长有以下几种方法。
a.当树到达一定深度的时候,停止树的生长。
b.当到达当前结点的样本数量小于某个阈值的时候,停止树的生长。
c.计算每次分类对测试集的准确度提升,当小于某个阈值的时候,不再继续扩展。
预剪枝具有思想直接、算法简单、效率高等特定,适合解决大规模问题。但 如何准确地估计何时停止树的生长(即上述方法中的深度或阈值),针对不同问题 会有很大差别,需要一定经验判断。且预剪枝存在一定局限性,有欠拟合的风险, 虽然当前的划分会导致测试集准确率降低,但在之后的划分中,准确率可能会有显 著上升。
2 后剪枝
后剪枝的核心思想是让算法生成一棵完全生长的决策树,然后从最底层向上计算是否剪枝。剪枝过程将子树删除,用一个叶子结点替代,该结点的类别同样按照多数投票的原则进行判断。同样地,后剪枝也可以通过在测试集上的准确率进行判 断,如果剪枝过后准确率有所提升,则进行剪枝。相比于预剪枝,后剪枝方法通常可以得到泛化能力更强的决策树,但时间开销会更大。
常见的后剪枝方法包括错误率降低剪枝(Reduced Error Pruning, REP)、悲观剪枝(Pessimisic Error Pruning,PEP)、代价复杂度剪枝(Cost Complexiy Pruning,CCP)、最小误差剪枝(Minimum Error Pruning,MEP)、CVP(Critical Value Pruning)、OPP(Optimal Pruning)等方法,这些剪枝方法各有利弊,关注不同的优化角度。
五、 代码实现
数据字段说明:
- User_id:用户ID
- Merchant_id:商户ID
- Coupon_id:优惠券ID;null表示无优惠券消费,此时Discount_rate和Date_received字段无意义
- Discount_rate:优惠率;x在[0,1]范围内时,代表折扣率;x:y表示满x减y。单位是元
- Distance:user经常活动的地点离该merchant的最近门店距离是x*500米(如果是连锁店,则取最近的一家门店),x在[0,10]区间;null表示无此信息,0表示低于500米,10表示大于5公里;
- Date_received:领取优惠券日期
- Date:消费日期,(Date - Date_received <= 15) 表示领取优惠券且在15天内使用,即正样本,y = 1;(Date - Date_received > 15)表示领取优惠券未在15天内使用,即负样本,y = 0
import pandas as pd
import numpy as np
# 导入DecisionTreeClassifier模型
from sklearn.tree import DecisionTreeClassifier
# 导入 train_test_split,用于划分数据集和测试集
from sklearn.model_selection import train_test_split
# 导入 accuracy_score 评价指标
from sklearn.metrics import accuracy_score
trai
n_data = pd.read_csv('/data/course_data/AI/ccf_offline_stage1_train.csv')
# 读取数据后,一般首先看一下数据的基本情况
train_data.info()
# 查看前5条样本
train_data.head()
# 查看数据大小
print(train_data.shape)
print(train_data.shape)
train_data = train_data.dropna(how='any')
print(train_data.shape)
# [0,1] 表示折扣率
# x:y 表示满 x 减 y
print('Discount_rate 类型:\n',train_data['Discount_rate'].unique())
# 将 Discount_rate 转化为数值特征,object在pandas中代表字符串
train_data['Discount_rate'] = train_data['Discount_rate'].apply(getDiscountType)
# 为数据集添加一个label列, 定义样本标签函数
def label(row):
# 计算用户消费日期和领取优惠券的时间间隔
td = pd.to_datetime(row['Date'], format='%Y%m%d') - pd.to_datetime(row['Date_received'], format='%Y%m%d')
if td <= pd.Timedelta(15, 'D'): # 如果消费日期和领取优惠券的时间间隔小于等于15,则标签设置为1
return 1
else:
return 0
train_data['label'] = train_data.apply(label, axis=1)
# 统计正负样本的分布
# Tips:当正负样本比例差距过大时(比如正负样本比例为1:10时),此时的数据集称为非平衡数据集,非平衡数据集会影响我们的模型,
# 因此需要对数据集进行处理,方法包括:正采样、负采样、数据合成等
# 具体方法可以参考这篇文章: https://blog.csdn.net/a8039974/article/details/83684841
print(train_data['label'].value_counts())
# 对数据集进行划分:80%训练集 、20%测试集
# stratify 其测试与训练标签的比例 同 输入的数组中标签的比例
X_train, X_test, y_train, y_test = train_test_split(train_data.iloc[:, 0:6],
train_data.iloc[:, 7],
test_size=0.2,
random_state=3,
stratify=train_data.iloc[:, 7])
# 查验测试样本的数量和类别分布
y_test.value_counts()
# 初始化分类决策树模型, 树的深度为5层
model = DecisionTreeClassifier(max_depth=5, random_state=1)
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 模型评估
accuracy_score(y_test, y_pred)
# 将模型选择特征的标准改为entropy
model = DecisionTreeClassifier(criterion='entropy', random_state=1, max_depth=5)
# 再次训练查看结果情况
六、知识点总结
知识点1:pandas关于时间的教程https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_datetime.html
知识点2:在sklearn中划分数据集有多种方法,比如当采用k折交叉验证时使用KFold函数;当采用留一法时使用LeaveOneOut函数; 更多的数据集划分方法可以参考这篇文章:https://www.cnblogs.com/cmybky/p/11772655.html
知识点3:在模型中,我们使用了"User_id"等6个特征,我们使用的6个特征是否对预测我们的label都有意义呢?我们是否能够构造更多有效的特征来纳入模型,以提高我们模型的预测的效果呢?