决策树(实战)
目录
实战部分将结合着 理论部分 进行,旨在帮助理解和强化实操(以下代码将基于 jupyter notebook 进行)。
一、准备工作(设置 jupyter notebook 中的字体大小样式等)
python">import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
二、树模型的可视化展示
决策树不仅在理论上很容易理解(机器学习“最友好”的算法),实现时还能对构建过程进行可视化(诸如神经网络等算法本身就是黑盒模型,更难可视化展示模型的构建)。因此,决策树的另一大优势就是能利用相关包来查看构建的树模型。下面介绍一个可以对决策树进行可视化展示的包:
下载链接:Graphviz 。
注:为了能在 cmd 中调用指令,在安装时需配置环境变量(下载exe文件,在安装过程中勾选 Add PATH)。
1、通过鸢尾花数据集构建一个决策树模型
python"># 导入鸢尾花数据集 和 决策树的相关包
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 加载鸢尾花数据集
iris = load_iris()
# 选用鸢尾花数据集的特征
# 尾花数据集的 4 个特征分别为:sepal length:、sepal width、petal length:、petal width
# 下面选用 petal length、petal width 作为实验用的特征
X= iris.data[:,2:]
# 取出标签
y = iris.target
# 设置决策树的最大深度为 2(也可以限制其他属性)
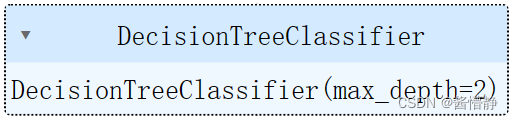
tree_clf = DecisionTreeClassifier(max_depth = 2)
# 训练分类器
tree_clf.fit(X, y)
2、对决策树进行可视化展示的具体步骤
python"># 导入对决策树进行可视化展示的相关包
from sklearn.tree import export_graphviz
export_graphviz(
# 传入构建好的决策树模型
tree_clf,
# 设置输出文件(需要设置为 .dot 文件,之后再转换为 jpg 或 png 文件)
out_file="iris_tree.dot",
# 设置特征的名称
feature_names=iris.feature_names[2:],
# 设置不同分类的名称(标签)
class_names=iris.target_names,
rounded = True,
filled = True
)
# 该代码执行完毕后,此 .ipython 文件存放路径下将生成一个 .dot 文件(名字由 out_file 设置,此处我设置的文件名为 iris_tree.dot)
接下来可以打开 cmd 用 graphviz 包中的 dot 命令将 .dot 文件转换为各种格式,如 .png 或 .jpg。命令为:
$ dot -T[图片格式,如 ‘jpg’] [目标dot文件,如 ‘iris_tree.dot’] -o [转换后的文件名,如 ‘iris_tree.jpg’]
例如:dot -Tjpg iris_tree.dot -o iris_tree.jpg
输入指令,点击回车后,若未出现任何反应(如上图所示),则代表执行成功!打开 iris_tree.dot 文件存放的目录会看到里面生成了一张图片文件:iris_tree.jpg。点击查看,如下:
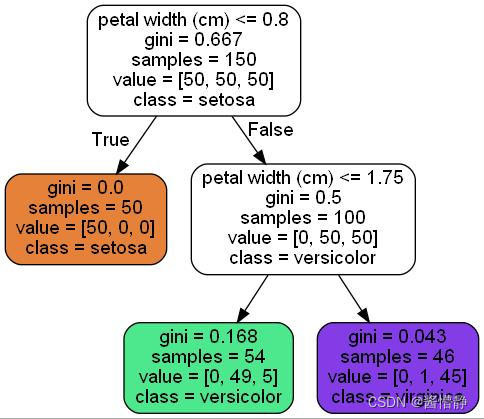
图像解读
- 上图中,根节点第一行数据是划分特征,可见根节点采用“花瓣长度”这个特征作为划分特征,判断条件是“花瓣宽度是否不大于 2.45”;
- 根节点第二行数据是基尼系数,可见根节点的基尼系数为 0.667;
- 根节点第三行数据是当前数据集的分类情况,可见在初始情况下,共有 3 类花(每类各 50 个);
- 根节点第四行数据表示在当前结点下,数据集被归类至哪一类。
3、概率估计
估计类概率:假设输入数据为:花瓣长 5cm,宽 1.5cm。从上图可以看出,其应当被分类至 versicolor 花。若要查看其归类概率,则决策树的输出如下:
- iris-Setosa 为 0% (0/54);
- iris-Versicolor 为 90.7% (49/54);
- iris-Virginica 为 9.3% (5/54)。
下面我们调用函数来查看各概率值:
python"># 调用函数查看概率估计
tree_clf.predict_proba([[5,1.5]])
Out
array([[0. , 0.90740741, 0.09259259]])
可以看出,通过函数计算出的估计值和我们计算出的结果基本一致。
python"># 调用函数查看预测结果
tree_clf.predict([[5,1.5]])
Out
array([1])
由于三类花及其索引分别为:
0 —— iris-Setosa;
1 —— iris-Versicolor;
2 —— iris-Virginica。
因此输出结果为:array([1])。
三、决策边界展示
定义绘制决策边界的函数:
python">from matplotlib.colors import ListedColormap
# 定义绘制决策边界的函数
def plot_decision_boundary(clf,X, y, axes=[0,7,0,3], iris=True,legend=False,plot_training=True):
# 构建坐标棋盘
# 等距选 100 个居于 axes[0],axes[1] 之间的点
x1s = np.linspace(axes[0],axes[1],100)
# x1s.shape = (100,)
# 等距选 100 个居于 axes[2],axes[3] 之间的点
x2s = np.linspace (axes[2],axes[3],100)
# x2s.shape = (100,)
# 构建棋盘数据
x1,x2 = np.meshgrid(x1s,x2s)
# x1.shape = x2.shape = (100,100)
# 将构建好的两个棋盘数据分别作为一个坐标轴上的数据(从而构成新的测试数据)
# x1.ravel() 将拉平数据(得到的是个列向量(矩阵)),此时 x1.shape = (10000,)
# 将 x1 和 x2 拉平后分别作为两条坐标轴
# 这里用到 numpy.c_() 函数,以将两个矩阵合并为一个矩阵
X_new = np.c_[x1.ravel(),x2.ravel()]
# 此时 X_new.shape = (10000,2)
# 对构建好的新测试数据进行预测
y_pred = clf.predict(X_new).reshape(x1.shape)
# 选用背景颜色
custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])
# 执行填充
plt.contourf(x1,x2,y_pred,alpha=0.3,cmap=custom_cmap)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2, y_pred,cmap=custom_cmap2,alpha=0.8)
if plot_training:
plt.plot(X[:,0][y==0],X[:,1][y==0],"yo", label="Iris-Setosa")
plt.plot(X[:,0][y==1],X[:,1][y==1],"bs", label="Iris-Versicolor")
plt.plot(X[:,0][y==2],X[:,1][y==2],"g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel (r"$x_2$", fontsize=18,rotation = 0)
if legend:
plt.legend(loc="lower right", fontsize=14)
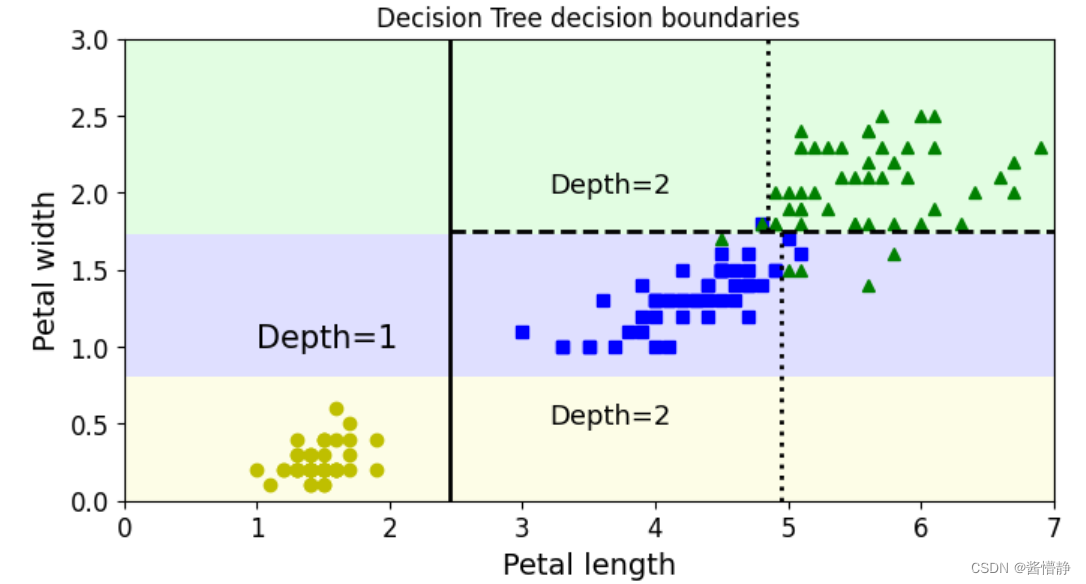
绘制决策边界:
python"># 绘制决策边界
plt.figure(figsize=(8,4))
plot_decision_boundary(tree_clf, X, y)
# 为了便于理解,这里还绘制了决策边界的切割线(基于前面得到的图片)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75,1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
# 绘制决策边界划分出的类别所处深度
plt.text(1, 1.0, "Depth=1", fontsize=15)
plt.text(3.2, 2, "Depth=2", fontsize=13)
plt.text(3.2,0.5, "Depth=2", fontsize=13)
plt.title('Decision Tree decision boundaries')
plt.show()
四、决策树的正则化(预剪枝)
DecisionTreeClassfilter 类中有以下限制决策树形状的参数(可用于做预剪枝操作):
- max_depth (决策树的最大深度)
- min_samples_split (结点在分割之前必须具有的最小样本数)
- min_samples_leaf (结点在分割之后其叶子结点必须具有的最小样本数)
- max_leaf_nodes (叶子结点的最大数量)
- max_features (在每个节点处评估用于拆分的最大特征数,通常情况下不限制这个参数)
接下来通过一个实验来测试 “限制 min_samples_leaf 属性” 对树模型的正则化效果(其他参数可照同样的方式进行测试,在此就不一一进行了):
python"># 这里选用一个难度稍微大一点的数据集
from sklearn.datasets import make_moons
# 构建数据集:X.shape = (100,2) y.shape = (100,)
X,y = make_moons(n_samples = 100, noise = 0.25, random_state = 43)
# 构建决策树
tree_clf1 = DecisionTreeClassifier(random_state = 6)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf = 5, random_state = 16)
tree_clf1.fit(X,y)
tree_clf2.fit(X,y)
# 画图展示:绘制决策边界
plt.figure(figsize=(12,4))
plt.subplot(121)
plot_decision_boundary(tree_clf1,X,y,axes = [-1.5, 2.5, -1, 1.5], iris = False)
plt.title('No Restrictions')
plt.subplot(122)
plot_decision_boundary(tree_clf2,X,y,axes = [-1.5, 2.5, -1, 1.5], iris = False)
plt.title('min_samples_leaf = 5')
其输出如下:
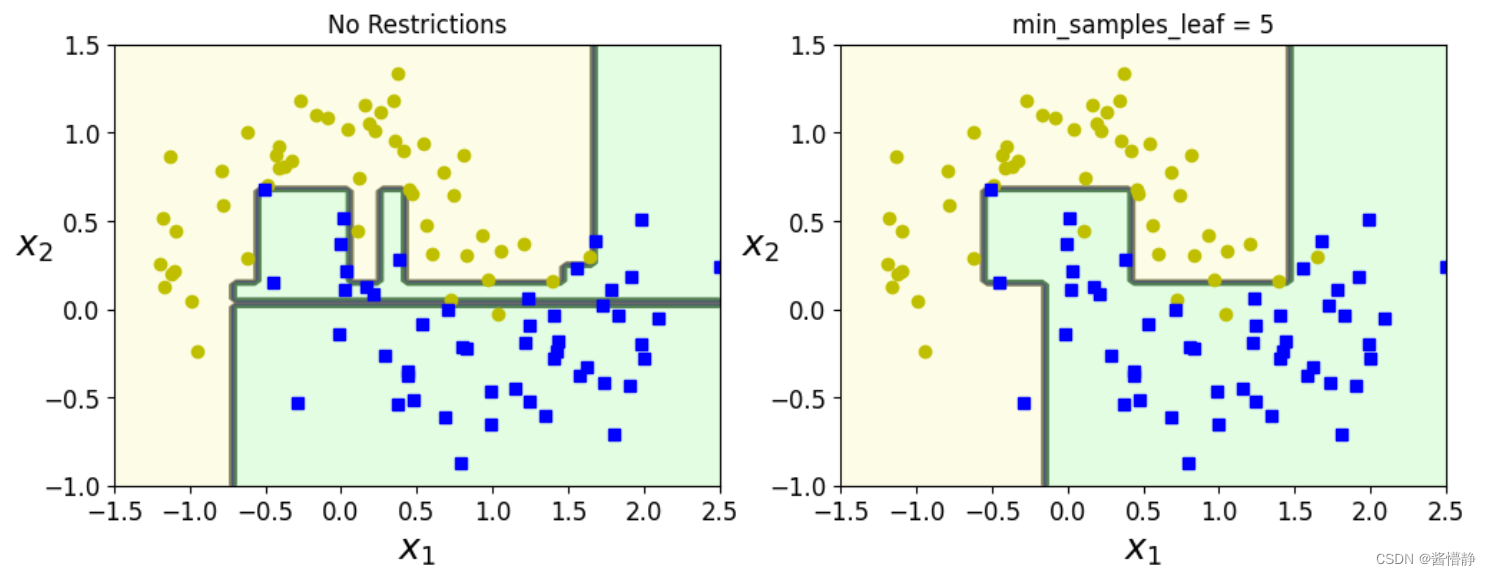
从上图可以得出以下结论:
- 左图在构建决策树时无限制,因此它能将所有数据点都归类好(不会出现任何离群点),所以其得到的决策树模型会相当复杂;但是,它出现了严重的过拟合现象。
- 右图由于加了限制,使得其构建的决策树模型不会过于复杂(奥卡姆剃刀原则:越简单的越好),但其分类效果自然也不会有左图那么高。
五、实验:探究树模型对数据的敏感程度
下面通过一个实验探究:当样本数据发生变动时,已构建好的模型是否依然稳定。
python"># 构建随机测试数据
np.random.seed(6)
Xs = np.random.rand(100,2) - 0.5
ys =(Xs[:, 0]> 0).astype(np.float32)*2
# 定义数据的旋转角度
angle = np.pi/ 4
# 旋转原始测试数据矩阵
rotation_matrix = np.array([[np.cos(angle),-np.sin(angle)],[np.sin(angle),np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix)
# 构建分类器 tree_clf_s 对原始数据进行训练
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs,ys)
# 构建分类器 tree_clf_sr 对处理后的数据进行训练
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr,ys)
# 绘图展示这两个分类器的测试效果
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf_s,Xs,ys,axes=[-0.7,0.7,-0.7,0.7], iris=False)
plt.title('Sensitivity to training set rotation')
plt.subplot(122)
plot_decision_boundary(tree_clf_sr,Xsr,ys,axes=[-0.7,0.7,-0.7,0.7],iris=False)
plt.title('Sensitivity to training set rotation')
plt.show()
其输出如下:

上图左边展示了对某数据集进行切割后得到的决策边界。接下来,将该数据集中的数据 “旋转” 45°,按理来说,其决策边界也会 “旋转” 45°,但根据上图右边的结果可以看出,决策边界并没有跟着旋转,而是采取了右边所示的方式重新绘制。
由此可见,决策树模型对数据非常敏感。
六、实验:用决策树解决回归问题
决策树在做分类或回归任务时,对应的数据集分别为离散型和连续性,因此这就导致其在评估时需要用不同的数学方法:
分类任务多用熵或基尼系数(从计算速度的角度来看更常用基尼系数);而回归任务则多用方差(方差是衡量一组数据之间相似程度的最简单的指标)。
python"># 导入相关库函数
from sklearn.tree import DecisionTreeRegressor
# 构造数据(一维数据)
m = 200
X = np.random.rand(m,1)
y = 4*(X-0.5)**2 + np.random.randn(m,1)/10
# 训练分类器
tree_reg = DecisionTreeRegressor(max_depth = 2)
tree_reg.fit(X,y)

python"># 树模型的展示
export_graphviz(
tree_reg,
out_file=("regression_tree.dot"),
feature_names=["x"],
rounded=True,
filled=True
)
接下来用 graphviz 包中的 dot 命令可得到以下决策树图片:

注:Sklearn中,默认生成的决策树为二叉树(CART)。
七、实验:探究决策树的深度对其拟合能力的影响
下面的实验将通过控制变量的方式,来探究两棵仅深度不同的决策树对样本数据的拟合能力差异。
设置两棵仅深度不同的树:
python"># 构建两棵深度不一致的决策树
tree_reg1 = DecisionTreeRegressor(random_state=42,max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42,max_depth=3)
# 训练分类器
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
定义相关函数:
python"># 定义预测回归值并绘制的函数
def plot_regression_predictions(tree_reg, X, y, axes=[0,1,-0.2,1],ylabel="$y$"):
# 获取棋盘坐标(这里的对象是一维坐标)
# reshape() 函数的 -1 表示对全部数据执行此函数执行后,数据由 (100,) 变为 (100,1)
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
# 得到预测值
y_pred = tree_reg.predict(x1)
# 绘图
plt.axis(axes)
plt.xlabel("$x_1$", fontsize=18)
if ylabel:
plt.ylabel(ylabel, fontsize=18, rotation=0)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred,"r.-", linewidth=2, label = r"$\hat{y}$")
查看差异:
python"># 开始绘制两个分类器的回归效果
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_regression_predictions(tree_reg1, X, y)
for split,style in ((0.1973, "k-"),(0.0917,"k--"),(0.7718,"k--")):
plt.plot([split,split],[-0.2,1],style,linewidth=2)
plt.text(0.21,0.65,"Depth=0", fontsize=15)
plt.text(0.01,0.2,"Depth=l", fontsize=13)
plt.text(0.65,0.8,"Depth=1", fontsize=13)
plt.legend(loc="upper center",fontsize=18)
plt.title("max_depth=2",fontsize=14)
plt.subplot(122)
plot_regression_predictions(tree_reg2,X, y,ylabel=None)
for split,style in ((0.1973,"k-"),(0.0917,"k--"),(0.7718,"k--")):
plt.plot([split,split],[-0.2,1], style,linewidth=2)
for split in (0.0458,0.1298,0.2873,0.9040):
plt.plot([split,split],[-0.2,1],"k:",linewidth=1)
plt.text(0.3,0.5,"Depth=2", fontsize=13)
plt.title("max_depth=3",fontsize=14)
plt.show()
得到的输出如下:
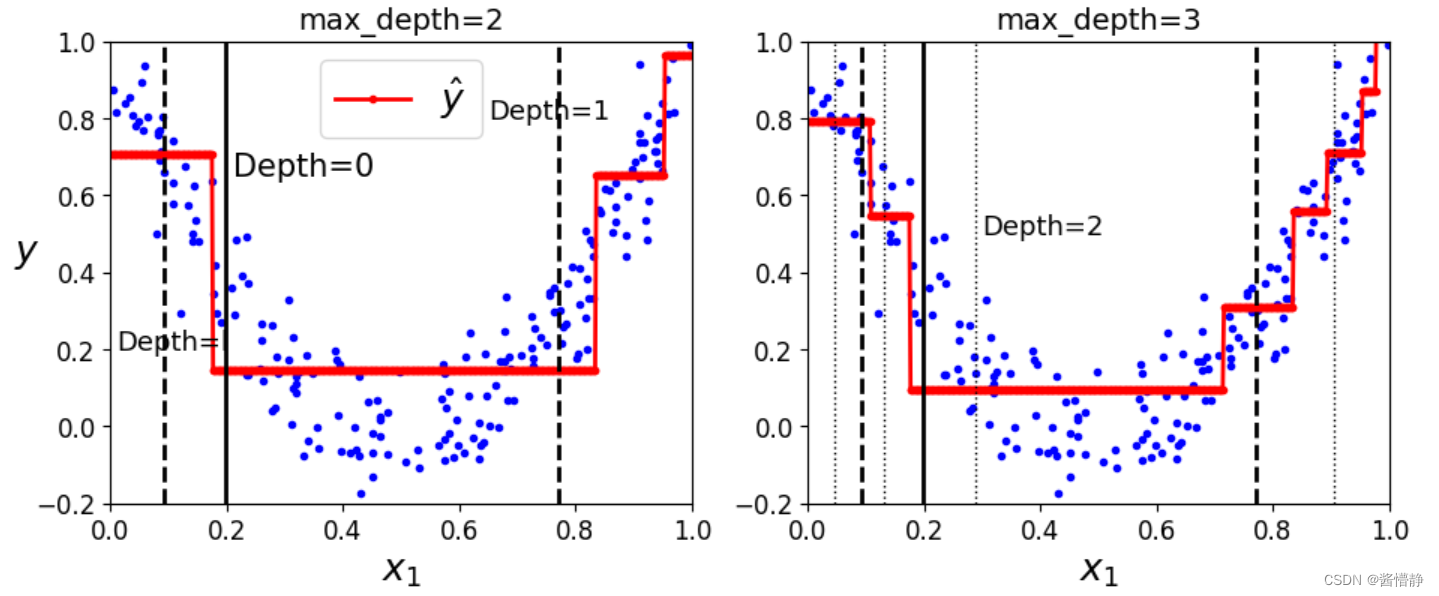
从上图可以看出,设置的 max_depth 越大,得到的决策树模型划分得越细,拟合效果越好。
接下来尝试将深度加大,看会出现什么效果:
python"># 不限制深度
tree_reg1 = DecisionTreeRegressor(random_state=42)
# 深度限制为 10
tree_reg2 = DecisionTreeRegressor(random_state=42,min_samples_leaf=10)
# 训练分类器
tree_reg1.fit(X,y)
tree_reg2.fit(X,y)
# 设置坐标数据(作为测试数据)
x1 = np.linspace(0,1,500).reshape(-1,1)
# 得到模型的预测值
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
绘图展示效果:
python"># 绘制两个分类器的回归效果
plt.figure(figsize=(11,4))
plt.subplot(121)
plt.plot(X, y,"b.")
plt.plot(x1,y_pred1,"r.-",linewidth=2,label=r"$\hat{y}$")
plt.axis([0,1,-0.2,1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
plt.subplot(122)
plt.plot(X, y,"b.")
plt.plot(x1,y_pred2,"r.-",linewidth=2,label=r"$ \hat{y}$")
plt.axis([0,1,-0.2,1.1])
plt.xlabel("$x_1$",fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf),fontsize=14)
plt.show ()
得到的输出如下:
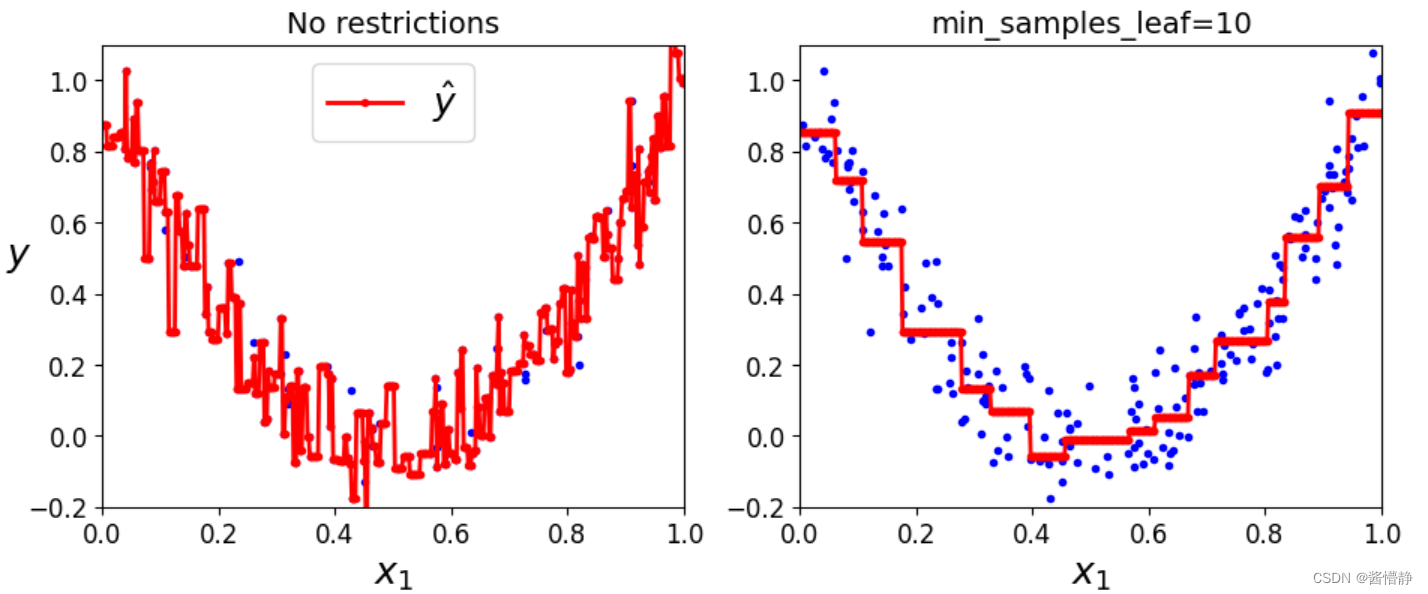
上图左边由于不加限制,所以出现了严重的过拟合现象(为了满足每个点,而将模型设置得相当复杂);而右图由于对 “叶子结点的最小样本数” 加了一定限制,故规避了过拟合风险。