数据的标准化方式
有两种常见的方法可以让所有的属性有相同的量度:线性函数归一化(Min-Max scaling)和标准化(standardization)。
方式 1:StandardScaler()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # SS方式
for clo in train_x.columns:#循环每一列
train_x[clo] = scaler.fit_transform(train_x[clo].values.reshape(-1, 1))
#转化函数为:z = (x - u) / s,Z为转化后的值,x为当 前值, u为均值, s为样本的标准差
代码解释:
该段代码使用了StandardScaler类从sklearn.preprocessing模块中进行数据标准化操作。
首先,创建了一个StandardScaler对象,并将其赋值给变量scaler。
然后,通过一个循环遍历train_x的每一列(特征):
- 针对每一列,将该列的值转换为一维数组形式,即使用
values.reshape(-1, 1)。 - 调用
scaler.fit_transform()方法,将该列的数据进行标准化转换。 - 最后,将标准化后的结果赋值回原始数据集的相应列
train_x[clo]。
这段代码的转换函数为:z = (x - u) / s,其中z为转换后的值,x为当前值,u为均值,s为样本的标准差。通过该标准化操作,可以使每一列的数据都按照其均值为0,标准差为1的分布进行转换,以便更好地适应机器学习算法的训练和预测过程。
方式 2:归一化(normalization)
线性函数归一化(许多人称其为归一化(normalization))很简单:值被转变、重新缩放,直到范围变成 0 到 1。我们通过减去最小值,然后再除以最大值与最小值的差值,来进行归一化。Scikit-Learn 提供了一个转换器MinMaxScaler来实现这个功能。它有一个超参数feature_range,可以让你改变范围,如果不希望范围是 0 到 1。
python">from sklearn.preprocessing import StandardScaler, MinMaxScaler
std_scaler = StandardScaler()
mm_scaler = MinMaxScaler()
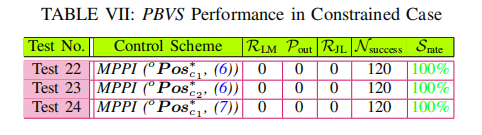
python">housing_num_ss = std_scaler.fit_transform(housing_num)
housing_num_ss
Reference
手把手带你开启机器学习之路——房价预测(一)
二、端到端的机器学习项目(StatLib 的加州房产价格数据集)