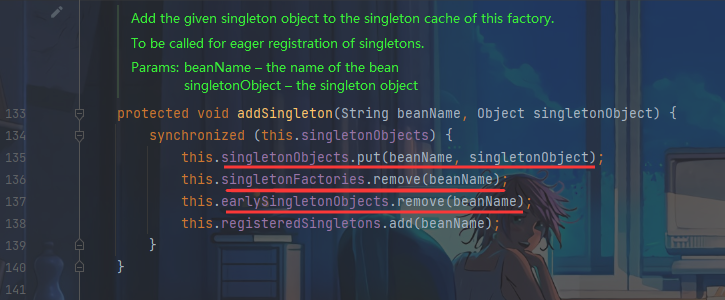
`scikit-learn`(或`sklearn`)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的`sklearn.preprocessing`模块中的类和功能:
1. 数据缩放和中心化:
- `StandardScaler`: 将数据进行标准化,使得每个特征的均值为0,方差为1。
- `MinMaxScaler`: 将数据缩放到指定的最小值和最大值之间(通常是0到1)。
- `RobustScaler`: 对数据进行缩放,可以抵抗异常值的影响。
- `MaxAbsScaler`: 将数据按特征的绝对值最大缩放。
2. 类别特征编码:
- `LabelEncoder`: 将类别变量编码为整数标签。
- `OneHotEncoder`: 将类别变量转换为二进制编码的多个列。
3. 缺失值处理:
- `SimpleImputer`: 使用均值、中位数、众数等填充缺失值。
- `KNNImputer`: 使用最近邻的值来填充缺失值。
4. 数据变换:
- `PolynomialFeatures`: 通过创建多项式特征扩展特征空间。
- `FunctionTransformer`: 通过自定义函数对数据进行转换。
5. 数据分箱(Binning):
- `KBinsDiscretizer`: 将连续特征分成离散的箱子。
6. 正则化:
- `Normalizer`: 对样本进行归一化,使其具有单位范数。
7. 特征选择:
- `SelectKBest`: 基于统计测试选择排名前k个最好的特征。
- `RFE`(递归特征消除):逐步选择特征,通过迭代来识别最重要的特征。
8. 数据流水线(Pipeline):
- `Pipeline`: 将多个数据预处理步骤和模型训练步骤连接起来,以便更好地管理工作流程。
这些只是`sklearn.preprocessing`模块中提供的一些常见功能。你可以根据数据和问题的特点选择适合的预处理步骤来优化机器学习模型的性能。要使用这些工具,你需要首先安装`scikit-learn`库,并在代码中导入相应的类。
将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from matplotlib improt gridspec
import numpy as np
import matpotlib.pyplot as plt1)StandardScaler
cps = np.random.random_integers(0, 100, (100, 2))
# 创建StandardScaler 对象,再调用fit_transform 方法,传入一个格式的参数数据作为训练集.
ss = StandardScaler()
std_cps = ss.fit_transform(cps)
gs = gridspec.GridSpec(5,5)
fig = plt.figure()
ax1 = fig.add_subplot(gs[0:2, 1:4])
ax2 = fig.add_subplot(gs[3:5, 1:4])
ax1.scatter(cps[:, 0], cps[:, 1])
ax2.scatter(std_cps[:, 0], std_cps[:, 1])
plt.show()2) MinMaxScaler
MinMaxScaler:使得特征的分布在一个给定的最小值和最大值的范围内.一般情况下载0`1之间(为了对付哪些标准差相当小的特征并保留下稀疏数据中的0值.)
min_max_scaler = preprocessing.MinMaxScaler()
x_minmax = min_max_scaler.fit_transform(x)3)MaxAbsCaler
MaxAbsScaler:数据会被规模化到-1`1之间,就是特征中,所有数据都会除以最大值,该方法对哪些已经中心化均值为0,或者稀疏的数据有意义.
max_abs_scaler = preprocessing.MaxAbsScaler()
x_train_maxsbs = max_abs_scaler.fit_transform(x)
x_train_maxsbs4) 正则化Normalization
正则化是将样本在向量空间模型上的一个转换,常常被使用在分类和聚类中,使用函数normalize实现一个单向量的正则化功能.正则化化有I1,I2等
x_normalized = preprocessing.normalize(x, norm='l2')
print(x)
5) 二值化
特征的二值化(指将数值型的特征数据转换为布尔类型的值,使用实用类Binarizer),默认是根据0来二值化,大于0的都标记为1,小于等于0的都标记为0.通过设置threshold参数来更改该阈值
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
binarizer = preprocessing.Binarizer().fit(x)
binarizer.transform(x)
binarizer = preprocessing.Binarizer(threshold=1.5)
binarizer.transform(x)6) 为类别特征编码
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
enc.transform([[0, 1, 3]]).toarray() # 进行编码7) 弥补缺失数据
import numpy as np
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit domain name is for sale. Inquire now.([[1, 2], [np.nan, 3], [7, 6]])
x = [[np.nan, 2], [6, np.nan], [7, 6]]
imp.transform(x)Imputer类同样也可以支持稀疏矩阵,以下例子将0作为了缺失值,为其补上均值
import scipy.sparse as sp
# 创建一个稀疏矩阵
x = sp.csc_matrix([[1, 2], [0, 3], [7, 6]])
imp = Imputer(missing_values=0, strategy='mean', verbose=0)
imp.fit domain name is for sale. Inquire now.(x)
x_test = sp.csc_matrix([[0, 2], [6, 0], [7, 6]])
imp.transform(x_test)