目录
- 1. 多层感知机原理
- 神经元概念
- 误差反向传播
- 更新权重
- 2. 公式推导
- 3. 实例
- 3.1. 数据集
- 3.2. python
- 3.3. torch
- 4. 几个注意点(面试问题)
- 5. 运行(可直接食用)
1. 多层感知机原理
神经元概念
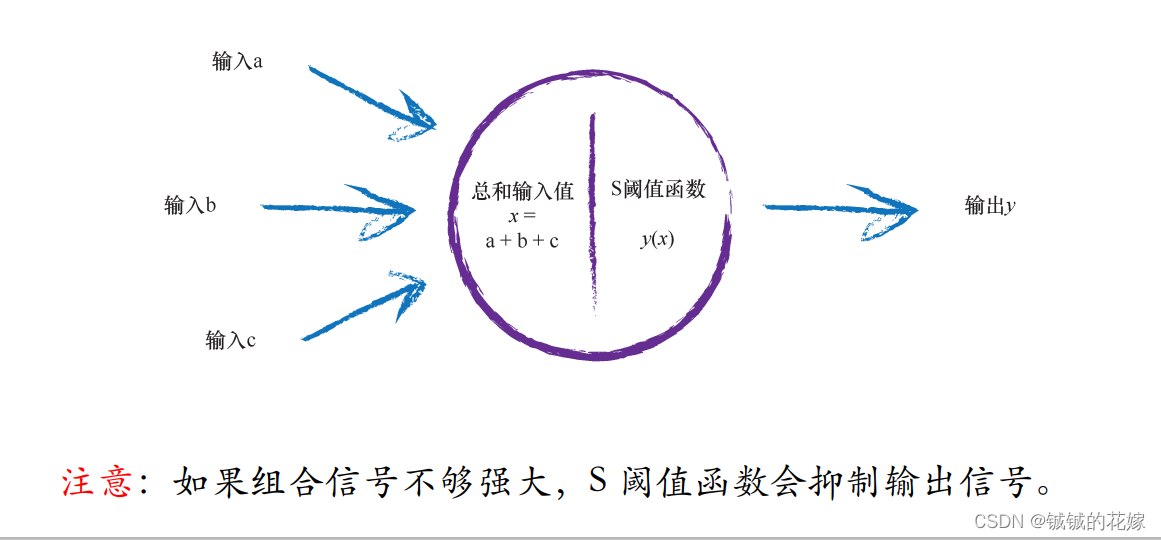
多层感知机就是由好几层神经元组成的,每个神经元包括输入,输出,阈值。
在神经元内部也会对输入进行处理,在过完阈值后还需要用激活函数把输出信号归拢到指定范围内。
激活函数有很多,但是需要记住,它最好具备连续光滑可导的性质,这也是为什么阶跃函数等经常会被淘汰。
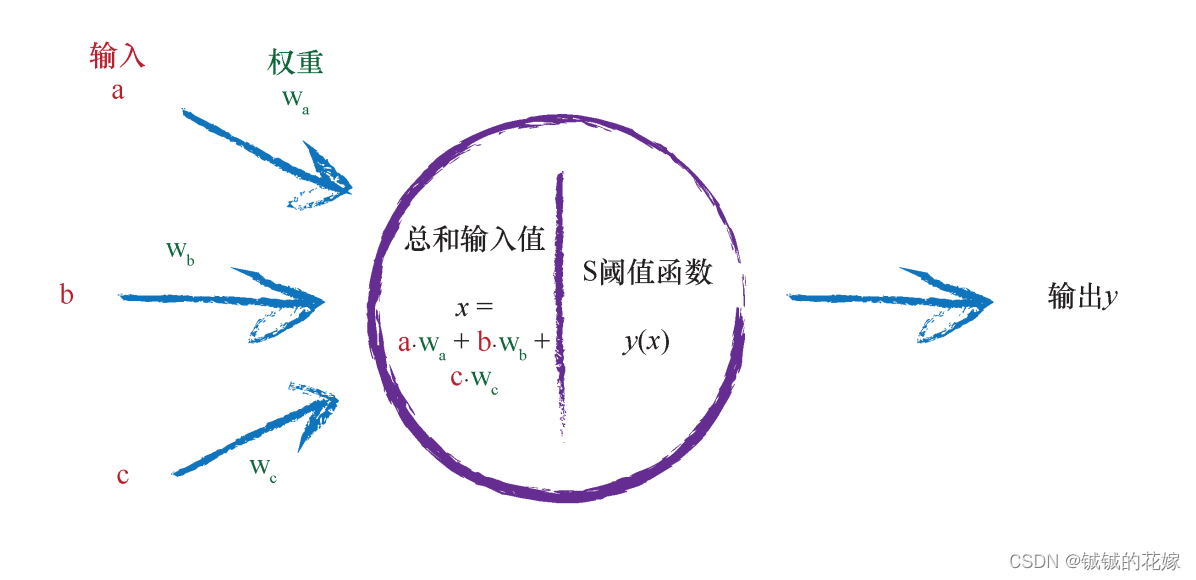
除此之外在神经网络内的求和处理也会用到权重,其实一个网络最后训练的就是这些权重应该怎么取,其他参数应该怎么取。
误差反向传播
刚刚梳理了单个神经元的知识点,我们现在回到神经网络中。在网络里数据是流动的,我们最终的目的是获得一个最好的 w 的组合,那么我们怎么判断这个 w 好不好?
误差
计算误差的方法也有很多,本质上度量神经⽹络的输出的预测值与实际值之间的差距的⼀种⽅式,称为损失函数,这里不过分强调。当我们知道误差之后,这个误差应该怎么去影响 w?
反向传播
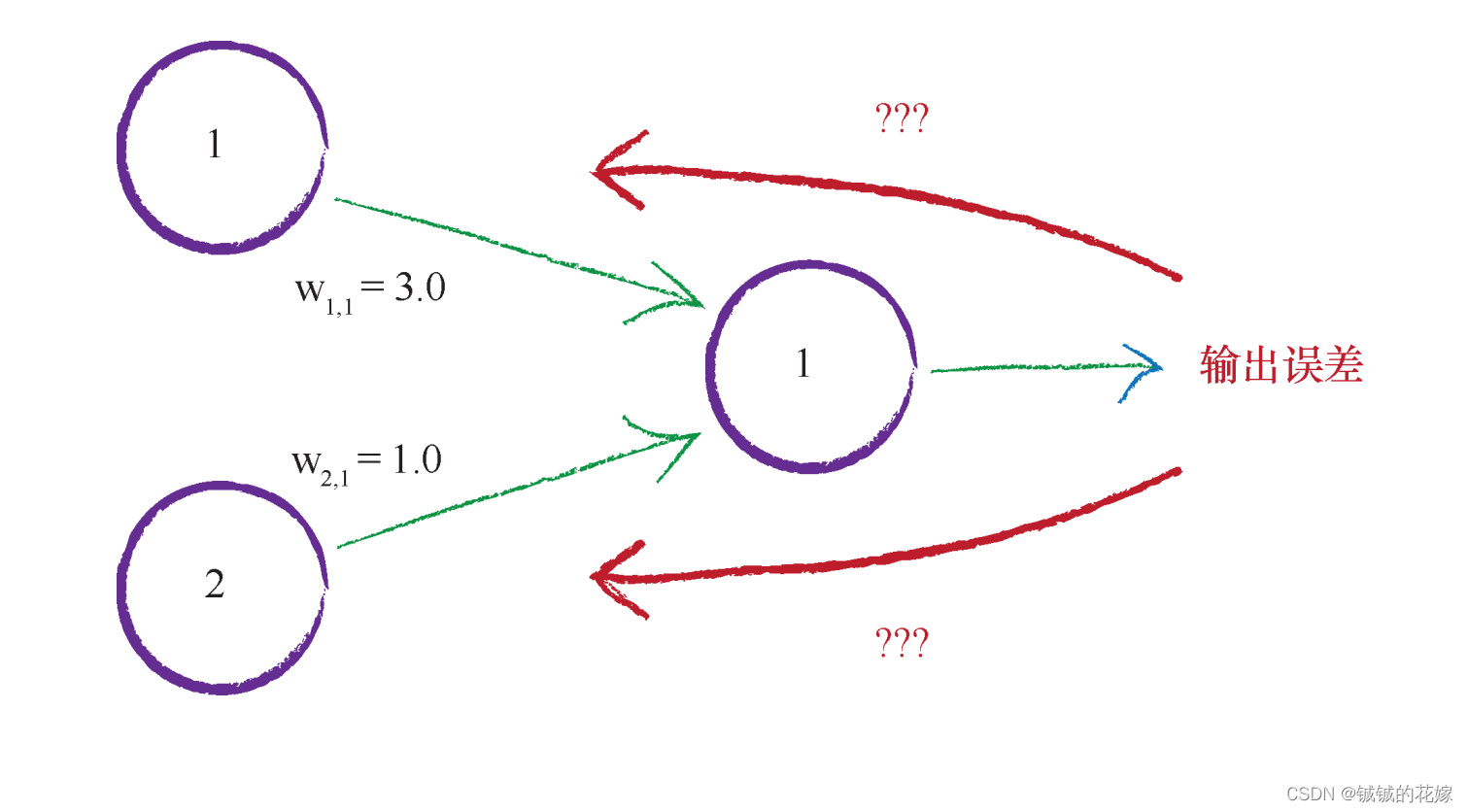
我们通过计算得到误差,再通过误差的大小反过来矫正之前的 w,那么下一次用到这个 w 就很有可能更准确。
我们观察上图,误差对于每个权重的影响也有权重,平分误差对这俩权重的影响显然是不公平的,这就出现了新的问题:如何更新权重?
更新权重
把损失值从神经⽹络的输出层反向传递到输⼊层的方法称为优化函数。
我们以梯度下降法为例。
梯度下降法的思想是通过求导找到一个高效的梯度,使得我们可以快速优化 w。好处是我们可以一步一步迭代接近最优解而不需要直接求解某个数学公式,因为这些公式求解太过困难。
为什么我们经常提到我们喜欢斜率容易计算、平滑连续、适合做误差函数的原因也在这里,面对含绝对值的或者是不连续的函数,在梯度下降求梯度时我们很难求导或者求导后会在某个范围不停波动无法接近最优解。
2. 公式推导
神经网络还好,不像SVM之类的要复习一下高数的知识啥的,这个就只需要自己计算就好了,会求导求积分就行。
假设我们有这么一个网络:
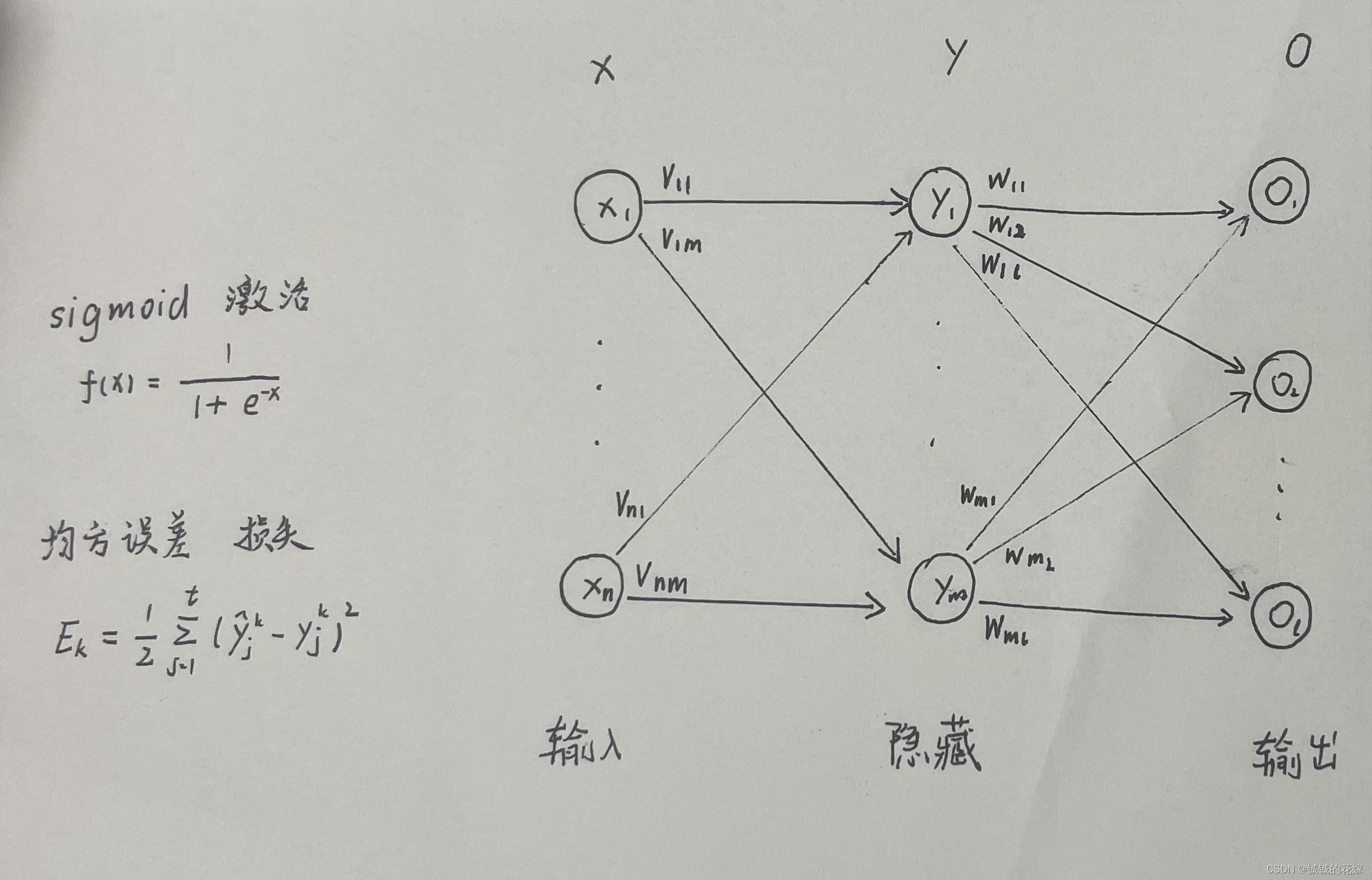
模拟一下流程

算出来了,转化为矩阵形式:
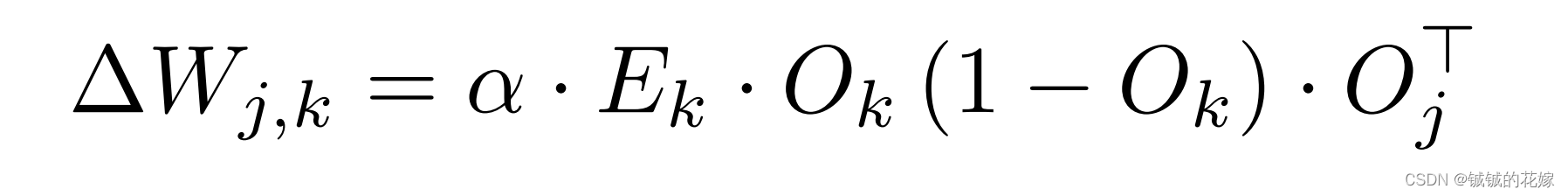
还需要再往前传播一层:

3. 实例
3.1. 数据集
手写数据集
链接
python_73">3.2. python
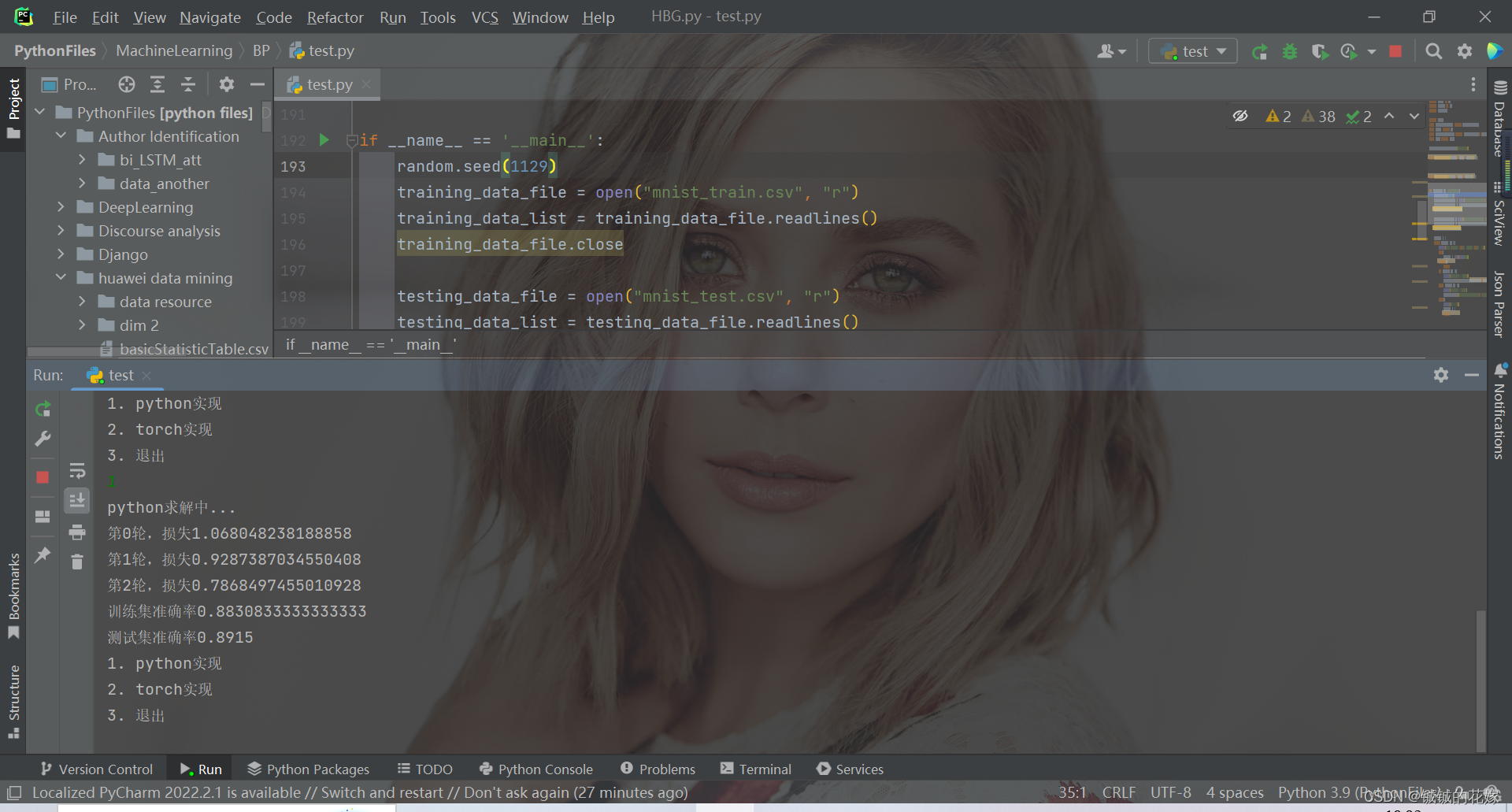
python">def python_finish(train, test, epoch):
inputSize = 784
hiddenSize = 256
outputSize = 10
lR = 0.001
class Net:
def __init__(self, input_size, hidden_size, output_size, lr):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lr = lr
# 激活函数
self.sigmoid = lambda x: 1 / (1 + np.exp(-x))
# 输入层和隐藏层之间的参数
self.v = np.random.normal(0.0, pow(self.hidden_size, -0.5), (self.hidden_size, self.input_size))
# 隐藏层和输出层之间的参数
self.w = np.random.normal(0.0, pow(self.output_size, -0.5), (self.output_size, self.hidden_size))
def train(self, data, label):
# 进入隐藏层(点乘)
hidden_in = np.dot(self.v, data)
# 激活输出
hidden_out = self.sigmoid(hidden_in)
# 进入输出层
output_in = np.dot(self.w, hidden_out)
# 出输出层
output_out = self.sigmoid(output_in)
# 更新参数w(上面那一长串)
self.w += self.lr * np.dot(((label-output_out) * output_out * (1 - output_out)), np.transpose(hidden_out))
# 太长了先写一段
t = np.dot(self.w.T, (label-output_out) * (1 - output_out) * output_out)
# 更新参数v
self.v += self.lr * np.dot((t * hidden_out * (1 - hidden_out)), np.transpose(data))
# 返回隐藏层和输出层的军方差的和
return (np.power((label-output_out), 2).sum() + np.power(t, 2).sum())
def predict(self, inputs):
hidden_inputs = np.dot(self.v, inputs)
Yj = self.sigmoid(hidden_inputs)
final_inputs = np.dot(self.w, Yj)
Ok = self.sigmoid(final_inputs)
return Ok
def get_acc(self, data):
sum = len(data)
true_n = 0
for d in data:
all_values = d.split(',')
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# 调整输入
pred = np.argmax(self.predict(np.array(inputs, ndmin=2).T))
if int(pred) == int(all_values[0]):
true_n += 1
return true_n / sum
bp_model = Net(input_size=inputSize, hidden_size=hiddenSize, output_size=outputSize, lr=lR)
for i in range(epoch):
# 每轮误差
error = []
# 得出个零头,left不能 == 0
left = 0.001
right = 1
for row in train:
data_row = row.split(',')
# 标准化下输入,asfarray转化为浮点数
data = (np.asfarray(data_row[1:])/255.0 * (right-left)) + left
# 除了正确数外全是left
label = np.zeros(outputSize) + left
label[int(data_row[0])] = right
# 最小二维np掉
error.append(bp_model.train(np.array(data, ndmin=2).T, np.array(label, ndmin=2).T))
print("第{}轮,损失{}".format(i, np.mean(error[-1])))
print("训练集准确率{}".format(bp_model.get_acc(train)))
print("测试集准确率{}".format(bp_model.get_acc(test)))
3.3. torch
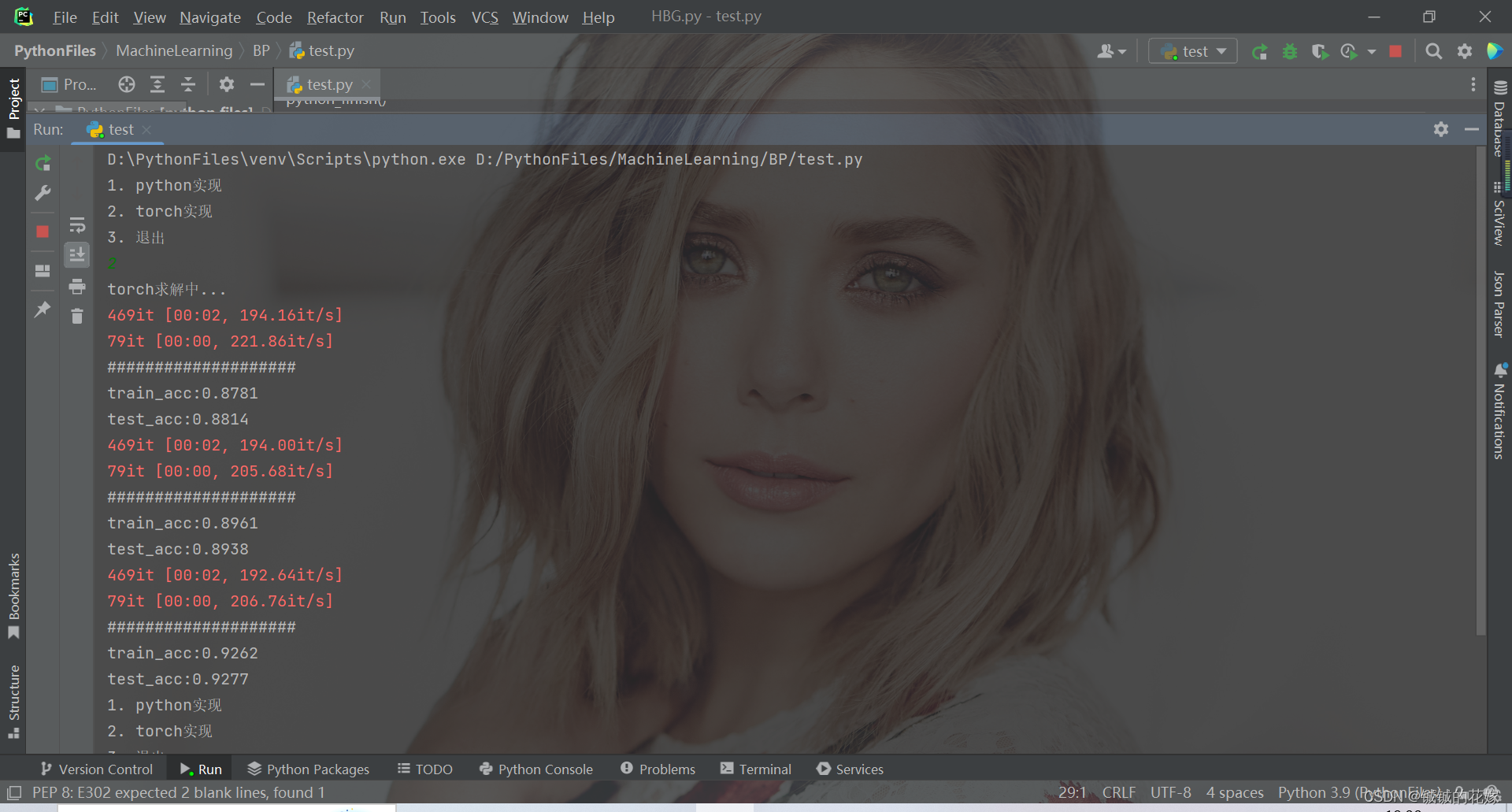
python">def torch_finish(train, test, epoch):
inputSize = 784
hiddenSize = 256
hiddenSize2 = 128
outputSize = 10
lR = 0.001
batchSize = 128
class NetWork(nn.Module):
def __init__(self, input_size, hidden_size, hidden_size2, output_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.hidden_size2 = hidden_size2
self.output_size = output_size
self.w1 = nn.Linear(input_size, hidden_size, bias=False)
self.w2 = nn.Linear(hidden_size, hidden_size2, bias=False)
self.w3 = nn.Linear(hidden_size2, output_size, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
i2h = self.w1(x)
i2h = self.sigmoid(i2h)
h2o = self.w2(i2h)
h2o = self.sigmoid(h2o)
o2j = self.w3(h2o)
o2j = self.sigmoid(o2j)
return o2j
def get_dataloader(batch_size, file_name):
filedata = pd.read_csv(file_name, header=None)
label = filedata.values[:, 0]
data = filedata.values[:, 1:]
data = torch.from_numpy(data).to(torch.float32)
label = torch.from_numpy(label).to(torch.long)
dataset = TensorDataset(data, label)
data_loader = dataloader.DataLoader(dataset=dataset, shuffle=True, batch_size=batch_size)
return data_loader
def evaluate_model(model, iterator, criterion):
all_pred = []
all_y = []
losses = []
for i, batch in tqdm(enumerate(iterator)):
if torch.cuda.is_available():
input = batch[0].cuda()
label = batch[1].type(torch.cuda.LongTensor)
else:
input = batch[0]
label = batch[1]
y_pred = model(input)
loss = criterion(y_pred, label)
losses.append(loss.cpu().detach().numpy())
predicted = torch.max(y_pred.cpu().data, 1)[1]
all_pred.extend(predicted.numpy())
all_y.extend(label.cpu().detach().numpy())
score = accuracy_score(all_y, np.array(all_pred).flatten())
return score, np.mean(losses)
model = NetWork(input_size=inputSize, hidden_size=hiddenSize, hidden_size2=hiddenSize2 ,output_size=outputSize)
optimizer = torch.optim.Adam(model.parameters(), lr=lR)
loss_func = nn.CrossEntropyLoss()
test_loader = get_dataloader(batch_size=batchSize, file_name=test)
train_loader = get_dataloader(batch_size=batchSize, file_name=train)
train_scores = []
test_scores = []
train_losses = []
test_losses = []
for epoch in range(epoch):
model.train() # 模型训练
for step, (x, label) in enumerate(train_loader):
pred = model(x)
loss = loss_func(pred, label) # 损失函数
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 优化器
model.eval() # 固定参数
train_score, train_loss = evaluate_model(model, train_loader, loss_func)
test_score, test_loss = evaluate_model(model, test_loader, loss_func)
train_losses.append(train_loss)
test_losses.append(test_loss)
train_scores.append(train_score)
test_scores.append(test_score)
print('#' * 20)
print('train_acc:{:.4f}'.format(train_score))
print('test_acc:{:.4f}'.format(test_score))
4. 几个注意点(面试问题)
神经网络有几个注意点,可能会在面试中被提到,还是比较能体现被面试者对这个算法的理解的。当然我们也不一定就是为了面试,搞清楚这些问题对帮助我们理解这个算法还是很有好处的。其中部分答案是博主自己的理解,如果有问题麻烦路过的大佬评论区指正。
- 当前只有两个输入时,需要几个隐含层的多层感知机能有效解决异或问题?
答:
在逻辑回归里面我们已经证明了它对异或问题无可奈何,在没有隐藏层时,神经网络在该问题下等同于逻辑回归。所以不止需要一个隐含层。
那如果是一个隐含层呢?
可以!
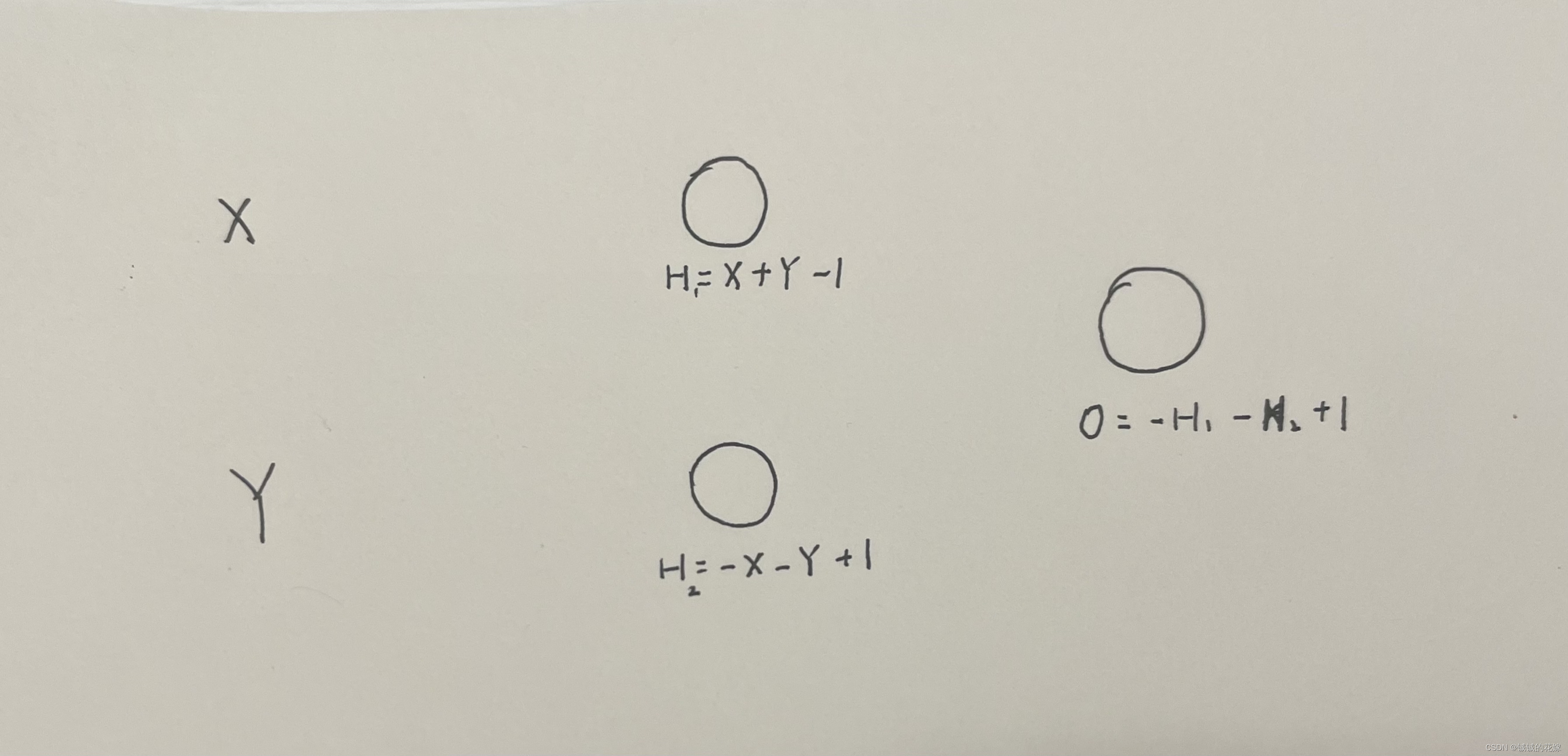
H1判断是否都为1,H2判断是否都为0,输出判断两个是否都达成了。
- 如果只有一个隐含层,需要多少个隐含节点能够实现包含 n 元输入的任意布尔函数?多个呢?
答:
2 ( n − 1 ) 2^{(n-1)} 2(n−1)
每多加一个输入都要判断跟其他几个所有的排列组合之间的关系。
3 ( n − 1 ) 3(n-1) 3(n−1) 个节点
三个结点可以完成一次异或操作,隐藏层有两个节点,一次异或操作可以作为2元的结果,把2元的结果编程下一个异或的其中之一输入,那么就可以通过加3个结点两层再多加入一元。所以n元需要 3 ( n − 1 ) 3(n-1) 3(n−1)个节点。层数为 [ ⌈ 2 l o g 2 N ⌉ , 2 ( n − 1 ) ] [\lceil2log_2N\rceil, 2(n-1)] [⌈2log2N⌉,2(n−1)]
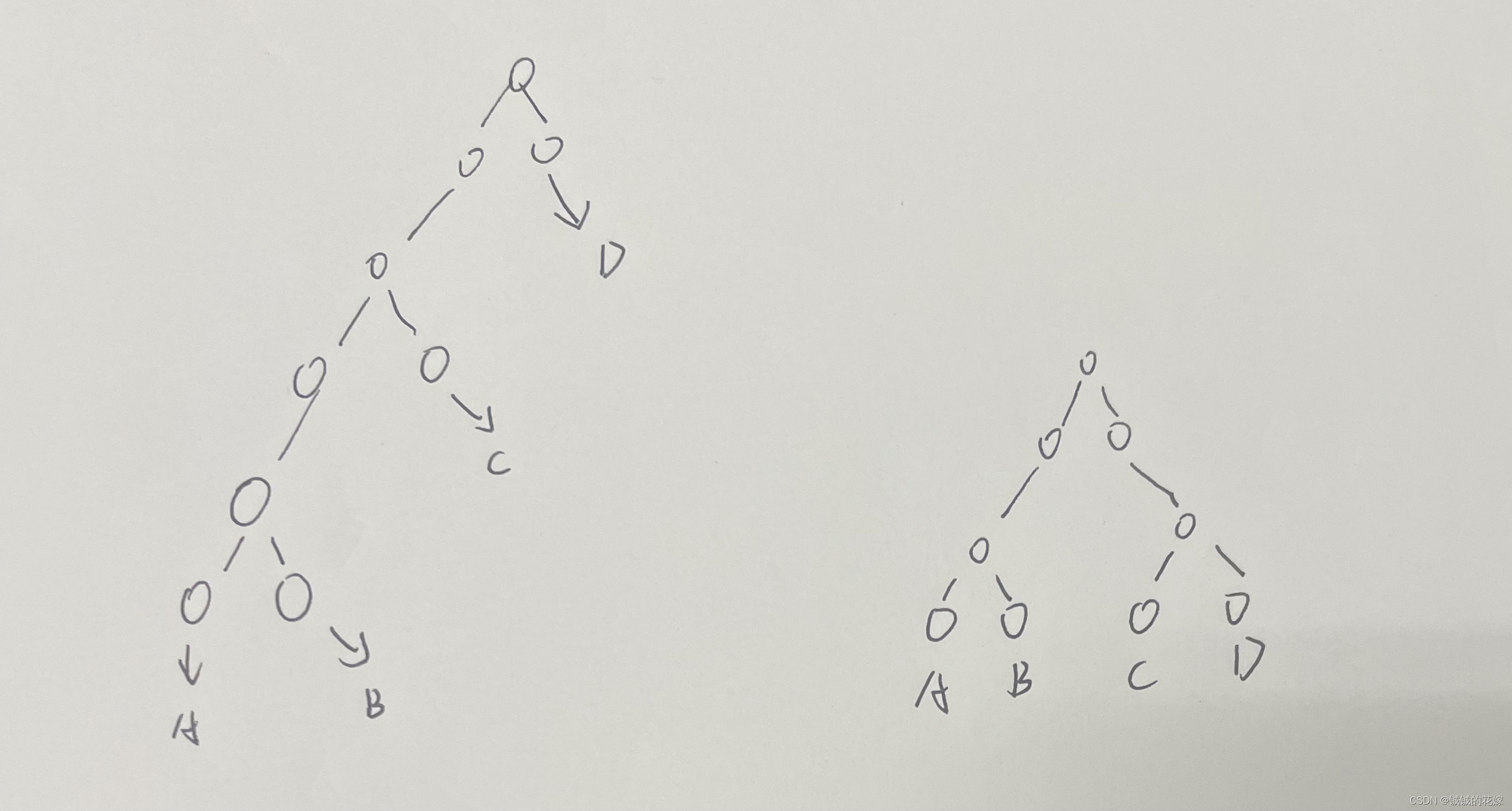
- 在考虑多个隐含层的情况下,实现包含n个输入的任意布尔函数至少需要多少个网络节点和网络层?
答:
- 为什么sigmoid函数会导致梯度消失?
答:
求导发现 f ( x ) ′ = f ( x ) ( 1 − f ( x ) ) f(x)^{'}=f(x)(1-f(x)) f(x)′=f(x)(1−f(x)),x取值很大或很小的时候 f ( x ) ′ f(x)^{'} f(x)′-> 0
- 将线性函数 f ( x ) = w T x f(x)=w^Tx f(x)=wTx作为神经元激活函数的缺陷?
答:
- 用sigmoid函数激活神经元和对数回归的关系?
答:
在一些情况下,没有隐含层的神经网络时等价对数回归。
对数几率回归 (分类): Sigmoid 函数的作用是将线性回归模型产生的预测值(实值)转化为 0/1 值。Sigmoid 函数是用于代替单位阶跃函数,因为Sigmoid 函数单调且可微.
神经元模型: Sigmoid 函数作为“激活函数”用以处理产生神经元的输出,其输出值为 (0, 1) 开区间内
- 推导BP的更新公式?
答:
上面写了,不赘述
- 学习率对神经网络训练的影响?
答:
控制训练的速度,lr过大可能导致再最优值附近徘徊无法接近,过小可能导致训练过慢。
- 神经网络参数能否全部随机初始化为0
答:
不可以。0乘任何数都是0.
5. 运行(可直接食用)
python">import random
import numpy as np
import pandas as pd
import warnings
import torch
from sklearn.metrics import accuracy_score
from torch import nn
from torch.utils.data import TensorDataset, dataloader
from tqdm import tqdm
warnings.filterwarnings("ignore")
def python_finish(train, test, epoch):
inputSize = 784
hiddenSize = 256
outputSize = 10
lR = 0.001
class Net:
def __init__(self, input_size, hidden_size, output_size, lr):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lr = lr
# 激活函数
self.sigmoid = lambda x: 1 / (1 + np.exp(-x))
# 输入层和隐藏层之间的参数
self.v = np.random.normal(0.0, pow(self.hidden_size, -0.5), (self.hidden_size, self.input_size))
# 隐藏层和输出层之间的参数
self.w = np.random.normal(0.0, pow(self.output_size, -0.5), (self.output_size, self.hidden_size))
def train(self, data, label):
# 进入隐藏层(点乘)
hidden_in = np.dot(self.v, data)
# 激活输出
hidden_out = self.sigmoid(hidden_in)
# 进入输出层
output_in = np.dot(self.w, hidden_out)
# 出输出层
output_out = self.sigmoid(output_in)
# 更新参数w(上面那一长串)
self.w += self.lr * np.dot(((label-output_out) * output_out * (1 - output_out)), np.transpose(hidden_out))
# 太长了先写一段
t = np.dot(self.w.T, (label-output_out) * (1 - output_out) * output_out)
# 更新参数v
self.v += self.lr * np.dot((t * hidden_out * (1 - hidden_out)), np.transpose(data))
# 返回隐藏层和输出层的军方差的和
return (np.power((label-output_out), 2).sum() + np.power(t, 2).sum())
def predict(self, inputs):
hidden_inputs = np.dot(self.v, inputs)
Yj = self.sigmoid(hidden_inputs)
final_inputs = np.dot(self.w, Yj)
Ok = self.sigmoid(final_inputs)
return Ok
def get_acc(self, data):
sum = len(data)
true_n = 0
for d in data:
all_values = d.split(',')
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# 调整输入
pred = np.argmax(self.predict(np.array(inputs, ndmin=2).T))
if int(pred) == int(all_values[0]):
true_n += 1
return true_n / sum
bp_model = Net(input_size=inputSize, hidden_size=hiddenSize, output_size=outputSize, lr=lR)
for i in range(epoch):
# 每轮误差
error = []
# 得出个零头,left不能 == 0
left = 0.001
right = 1
for row in train:
data_row = row.split(',')
# 标准化下输入,asfarray转化为浮点数
data = (np.asfarray(data_row[1:])/255.0 * (right-left)) + left
# 除了正确数外全是left
label = np.zeros(outputSize) + left
label[int(data_row[0])] = right
# 最小二维np掉
error.append(bp_model.train(np.array(data, ndmin=2).T, np.array(label, ndmin=2).T))
print("第{}轮,损失{}".format(i, np.mean(error[-1])))
print("训练集准确率{}".format(bp_model.get_acc(train)))
print("测试集准确率{}".format(bp_model.get_acc(test)))
def torch_finish(train, test, epoch):
inputSize = 784
hiddenSize = 256
hiddenSize2 = 128
outputSize = 10
lR = 0.001
batchSize = 128
class NetWork(nn.Module):
def __init__(self, input_size, hidden_size, hidden_size2, output_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.hidden_size2 = hidden_size2
self.output_size = output_size
self.w1 = nn.Linear(input_size, hidden_size, bias=False)
self.w2 = nn.Linear(hidden_size, hidden_size2, bias=False)
self.w3 = nn.Linear(hidden_size2, output_size, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
i2h = self.w1(x)
i2h = self.sigmoid(i2h)
h2o = self.w2(i2h)
h2o = self.sigmoid(h2o)
o2j = self.w3(h2o)
o2j = self.sigmoid(o2j)
return o2j
def get_dataloader(batch_size, file_name):
filedata = pd.read_csv(file_name, header=None)
label = filedata.values[:, 0]
data = filedata.values[:, 1:]
data = torch.from_numpy(data).to(torch.float32)
label = torch.from_numpy(label).to(torch.long)
dataset = TensorDataset(data, label)
data_loader = dataloader.DataLoader(dataset=dataset, shuffle=True, batch_size=batch_size)
return data_loader
def evaluate_model(model, iterator, criterion):
all_pred = []
all_y = []
losses = []
for i, batch in tqdm(enumerate(iterator)):
if torch.cuda.is_available():
input = batch[0].cuda()
label = batch[1].type(torch.cuda.LongTensor)
else:
input = batch[0]
label = batch[1]
y_pred = model(input)
loss = criterion(y_pred, label)
losses.append(loss.cpu().detach().numpy())
predicted = torch.max(y_pred.cpu().data, 1)[1]
all_pred.extend(predicted.numpy())
all_y.extend(label.cpu().detach().numpy())
score = accuracy_score(all_y, np.array(all_pred).flatten())
return score, np.mean(losses)
model = NetWork(input_size=inputSize, hidden_size=hiddenSize, hidden_size2=hiddenSize2 ,output_size=outputSize)
optimizer = torch.optim.Adam(model.parameters(), lr=lR)
loss_func = nn.CrossEntropyLoss()
test_loader = get_dataloader(batch_size=batchSize, file_name=test)
train_loader = get_dataloader(batch_size=batchSize, file_name=train)
train_scores = []
test_scores = []
train_losses = []
test_losses = []
for epoch in range(epoch):
model.train() # 模型训练
for step, (x, label) in enumerate(train_loader):
pred = model(x)
loss = loss_func(pred, label) # 损失函数
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 优化器
model.eval() # 固定参数
train_score, train_loss = evaluate_model(model, train_loader, loss_func)
test_score, test_loss = evaluate_model(model, test_loader, loss_func)
train_losses.append(train_loss)
test_losses.append(test_loss)
train_scores.append(train_score)
test_scores.append(test_score)
print('#' * 20)
print('train_acc:{:.4f}'.format(train_score))
print('test_acc:{:.4f}'.format(test_score))
if __name__ == '__main__':
random.seed(1129)
training_data_file = open("mnist_train.csv", "r")
training_data_list = training_data_file.readlines()
training_data_file.close
testing_data_file = open("mnist_test.csv", "r")
testing_data_list = testing_data_file.readlines()
testing_data_file.close
choice = 0
while choice != 3:
print("1. python实现\n2. torch实现\n3. 退出")
try:
choice = int(input())
except:
break
if choice == 1:
print("python求解中...")
python_finish(training_data_list,testing_data_list, 3)
elif choice == 2:
print("torch求解中...")
torch_finish("mnist_train.csv", "mnist_test.csv", 3)
else:
print("退出成功")
choice = 3
break
参考:
吴恩达《机器学习》
sklearn官网
《百面机器学习》