python">from sklearn import svm
from sklearn import datasets
import pickle # 保存模块
clf = svm.SVC()
iris = datasets.load_iris()
x, y = iris.data, iris.target
clf.fit(x, y)
"""方法一:使用 pickle 保存"""
# 保存Model(注:save文件夹要预先建立,否则会报错)
with open('save/clf.pickle', 'wb') as f:
pickle.dump(clf, f)
# 读取model
with open('save/clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
print(clf2.predict(x[0:1]))
"""使用 joblib 保存"""
import joblib
# 保存Model(注:save文件夹要预先建立,否则会报错)
joblib.dump(clf, "save/clf.pkl")
# 读取Model
clf3 = joblib.load('save/clf.pkl')
# 测试读取后的Model
print(clf3.predict(x[0:1]))
arcgis
定位
注解处理器
API
bootstrap
Listener
点图层
制图表达
web前端
shell 实现
rtmp
业界资讯
界面设计
线程同步
数据介绍
Java反射
自媒体
脚本实战
哈夫曼树
基础语法
sklearn模型保存
相关文章

机器学习——房屋价格预测【回归问题】
机器学习——房屋价格预测【回归问题】
1. 导工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(ignore) #过滤所有警告2. 读取数据
# 读取数据集
train pd.read_csv("…
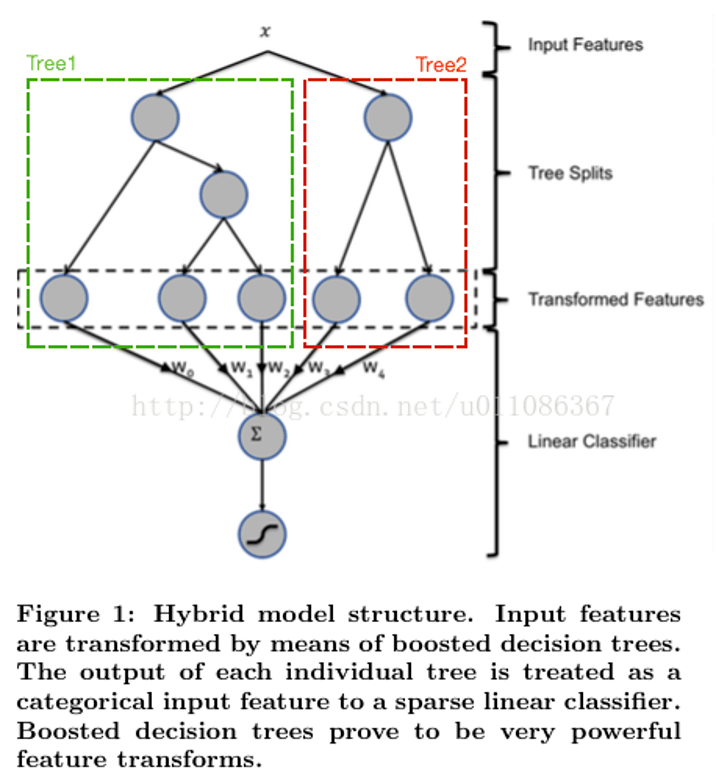
机器学习中的特征工程
机器学习中的特征工程
什么是特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。
构…
使用lgb.cv时出现ValueError: Supported target types are: (‘binary‘, ‘multiclass‘). Got ‘continuous‘ instea
使用lgb.cv时出现ValueError: Supported target types are: (‘binary’, ‘multiclass’). Got ‘continuous’ instead.
默认情况下,lightgbm.cv中的stratify参数是True。 根据the documentation:
stratified (bool, optional (defaultTrue)) – Whe…
Pytorch训练是出现pytorch RuntimeError: expected scalar type Double but found Float
错误如下
RuntimeError: expected scalar type Double but found Float原因: tensor的数据类型dtype不正确
解决: 将数据类型转为float32
tensor tensor.to(torch.float32)
贝叶斯调参报错:Object has no attribute ‘integers‘
报错版本:python version:3.9.7
hyperopt version:0.2.7
报错代码段:rstateRandomState(seed)
报错完整信息:
AttributeError: ‘numpy.random.mtrand.RandomState’ object has no attribute ‘integers’
解决方…
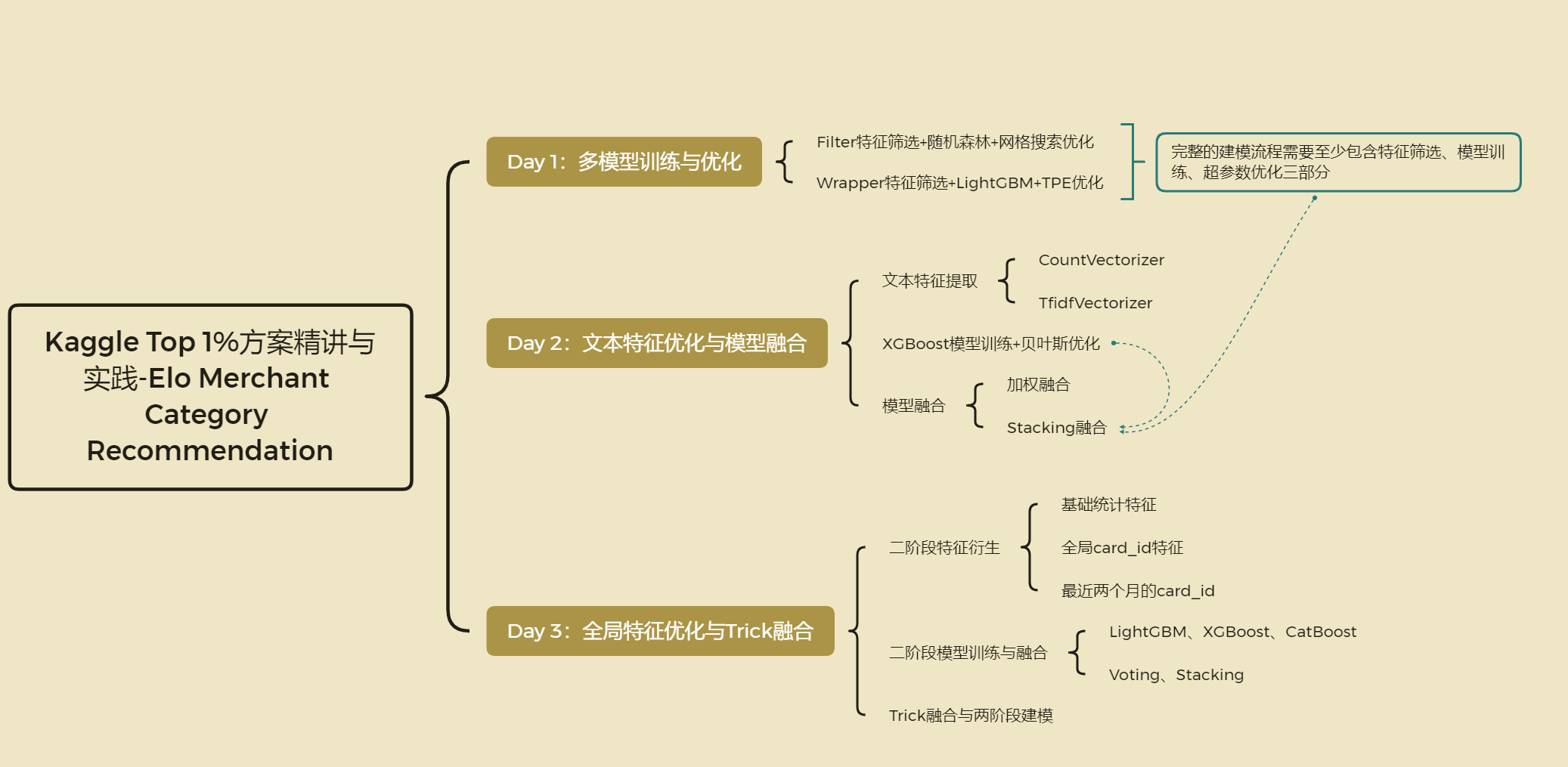
Kaggle-Elo Merchant Category Recommendation案例1%解决方案(特征工程)
数据预处理流程 思路 1. 数据读取
import gc
import time
import numpy as np
import pandas as pd
from datetime import datetime train pd.read_csv("train.csv")
test pd.read_csv("test.csv")
merchants pd.read_csv("merchants.csv")
…
Filter特征筛选+随机森林建模+网格搜索调优(Kaggle--Elo Merchant Category Recommendation)
数据预处理流程 思路 import pandas as pd
import numpy as np数据读取
train pd.read_csv("preprocess/train.csv")
test pd.read_csv("preprocess/test.csv")随机森林模型预测
特征选择–皮尔逊相关系数
(train.shape, test.shape)((201917, 1700),…
Filter特征筛选+随机森林建模+交叉验证(kaggle-Elo Merchant Category Recommendation)
数据预处理流程 思路 数据读取
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
from numpy.random import RandomState
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_errortrain pd.r…
最新文章
- 【C++】【MFC】绘图
- PyTorch 2-深度学习-模块
- Windows下编译OpenSSL静态库
- 堆溢出ret2libc
- ELB和VPC是云计算领域中的两个术语,通常与Amazon Web Services (AWS)相关联
- 百川工作手机实现销售管理微信监控系统
- 常用知识点问答
- 04从物理层到MAC层:如何在宿舍里自己组网玩联机游戏?
- MaxCompute表设计最佳实践
- [deviceone开发]-cnodejs论坛移动端App
- [Leetcode] Copy List with Random Pointer 复制随机指针
- [活动召集]福建PHP社区聚会
- [收藏]说声放弃太容易-Sunny