学习
时间复杂度
职场
kubernetes
网络攻击模型
注释
kudu读写流程
uml
sql注入
网络管理
startup packet
主备
pytorch配置GPU版本
坑人
图像分类
mq
小世界网络
启动过程
AIR32
解压
过拟合
2024/4/12 4:53:57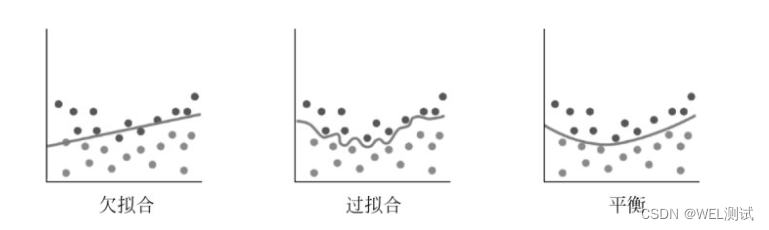
【机器学习】欠拟合与过拟合
过拟合:模型在训练数据上表现良好对不可见数据的泛化能力差。
欠拟合:模型在训练数据和不可见数据上泛化能力都很差。
欠拟合常见解决办法:
(1)增加新特征,可以考虑加入特征组合、高次特征,以…

过拟合和欠拟合是什么?有什么异同点?解决办法是什么?
过拟合(Overfitting)和欠拟合(Underfitting)是机器学习中两种常见的模型训练问题。
1、过拟合
过拟合指的是模型在训练数据上表现得很好,但在未见过的测试数据上表现较差的情况。过拟合通常发生在模型过于复杂、参数…
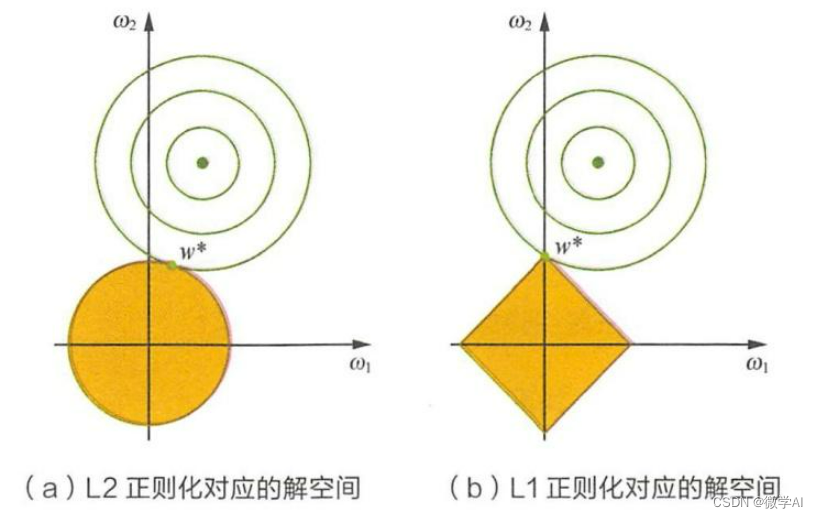
深度学习技巧应用35-L1正则化和L2正则在神经网络模型训练中的应用
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用35-L1 正则化和L2正则在神经网络模型训练中的应用。L1正则化和L2正则化是机器学习中常用的两种正则化方法,用于防止模型过拟合并提高模型的泛化能力。这两种正则化方法通过在损失函数中添加惩罚项来控制模型的复杂性。…
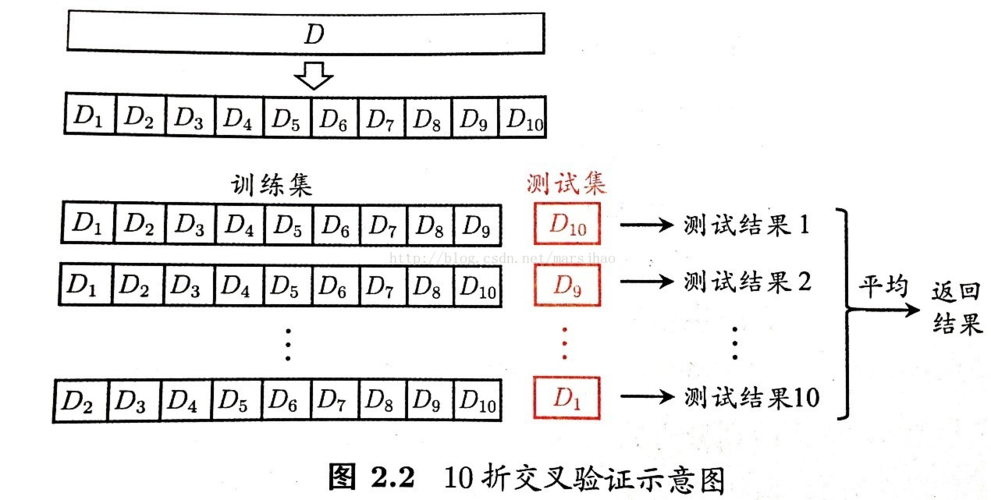
机器学习之过拟合与欠拟合,K折交叉验证详解【含代码】
欠拟合
欠拟合(Underfitting)是机器学习和统计学中的一个术语,描述了模型在训练数据和新数据(如测试数据或验证数据)上都表现不佳的情况。换句话说,欠拟合的模型没有足够地“学习”或“捕捉”数据中的模式…

R-Drop:更强大的Dropout正则方法
文章目录1 背景介绍1.1 Dropout技术1.2 Regularized Dropout (R-Drop)技术2 R-Dropout的原理介绍2.1 模型解释3 总结写在前面:本文学习引用微软研究院AI头条、“肉丸先生呀”的博文“R-Drop——更强大的Dropout”1 背景介绍
1.1 Dropout技术
深度神经网络…

深度学习图像数据增强:翻转、旋转、拉伸、五部分提取、明暗度变化python
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
一:日志依赖
https://blog.csdn.net/weixin_41803874/article/details/81201807 数据操作完整源码自 …
python中datetime的用法
python中datetime的用法 1、用法 #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import datetimedates datetime.datetime(2020, 10, 31,12,13)
print(dates.year) # 2020
print(dates.month) # 10
print(dates.day) # 31
print(dates.hour) # 12
print(dates.minute) # …

欠拟合、过拟合、正则化、学习曲线
1.欠拟合、过拟合、正则化、学习曲线
1.1 欠拟合、过拟合
欠拟合:模型相对于要解决的问题来说太简单了,模型并没有拟合训练数据的状态 过拟合:模型相对于要解决的问题来说太复杂了,模型只能拟合训练数据的状态
下图来自&#x…

机器学习笔记之正则化(二)权重衰减角度(直观现象)
机器学习笔记之正则化——权重衰减角度[直观现象]引言回顾:拉格朗日乘数法角度观察正则化过拟合的原因:模型参数的不确定性正则化约束权重的取值范围L1L_1L1正则化稀疏权重特征的过程权重衰减角度观察正则化场景构建权重衰减的描述过程权重衰减与过拟合…
![[CS229学习笔记] 3.欠拟合与过拟合,局部加权线性回归,线性回归的概率解释,逻辑回归,及感知机学习算法](https://img-blog.csdnimg.cn/20191016232203707.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzIyOTQzMzk3,size_16,color_FFFFFF,t_70#pic_center)
[CS229学习笔记] 3.欠拟合与过拟合,局部加权线性回归,线性回归的概率解释,逻辑回归,及感知机学习算法
本文对应的是吴恩达老师的CS229机器学习的第三课。这节课介绍了欠拟合与过拟合;然后介绍了参数学习算法与非参数学习算法,并例举了非参数学习算法的一个经典例子:局部加权线性回归;接着延续第二节课的内容讲解了线性回归的概率解释…
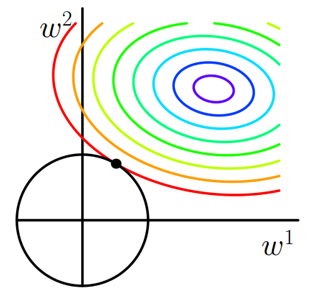
为什么正则化能够解决过拟合问题?
为什么正则化能够解决过拟合问题一. 正则化的解释二. 拉格朗日乘数法三. 正则化是怎么解决过拟合问题的1. 引出范数1.1 L_0范数1.2 L_1范数1.3 L_2范数2. L_2范式正则项如何解决过拟合问题2.1 公式推导2.2 图像推导[^2]2.2.1 L1正则化2.2.2 L2正则化四. 结论如果觉得不想看前两…

Keras - Dropout 理论与实践
一.引言 Dropout 层用于解决过拟合的问题,当原始样本偏少而深度模型参数偏多时,模型偏向于学习一些极端的特征从而导致过拟合,在训练样本上达到很高的精度但在测试集的表现却很糟糕,这时候可以引入 Dropout 按适当的比例舍弃掉一些…
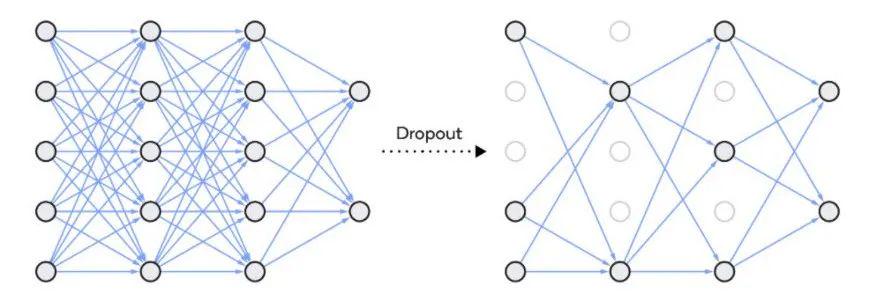
【一文速通】五个主流过拟合解决方法
过拟合是一个需要解决的问题,因为它会让我们无法有效地使用现有数据。有时我们也可以在构建模型之前,预估到会出现过拟合的情况。通过查看数据、收集数据的方式、采样方式,错误的假设,错误表征能够发现过拟合的预兆。为避免这种情…
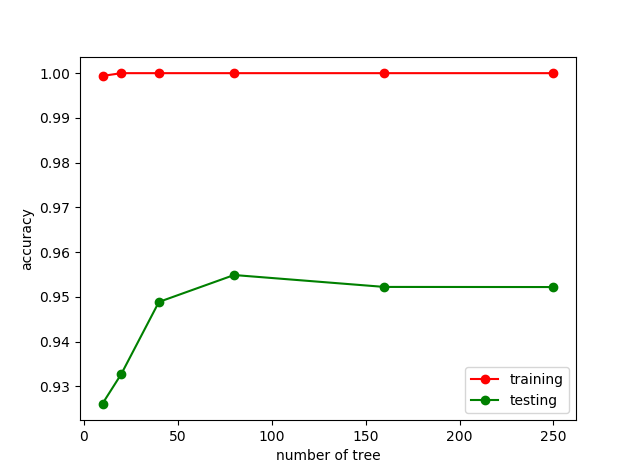
sklearn模型调优(判断是否过过拟合及选择参数)
sklearn模型调优(判断是否过过拟合及选择参数)这篇博客主要介绍两个方面的东西,其实就是两个函数:
1. learning_curve():这个函数主要是用来判断(可视化)模型是否过拟合的,关于过拟…

人工智能基础_机器学习022_使用正则化_曼哈顿距离_欧氏距离_提高模型鲁棒性_过拟合_欠拟合_正则化提高模型泛化能力---人工智能工作笔记0062
然后我们再来看一下,过拟合和欠拟合,现在,实际上欠拟合,出现的情况已经不多了,欠拟合是
在训练集和测试集的准确率不高,学习不到位的情况.
然后现在一般碰到的是过拟合,可以看到第二个就是,完全就把红点蓝点分开了,这种情况是不好的,
因为分开是对训练数据进行分开的,如果来…
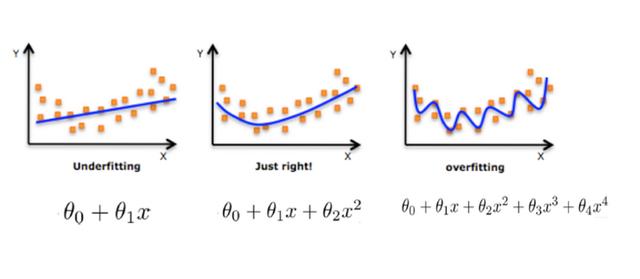
每天五分钟机器学习:如何解决过拟合问题?
本文重点
过拟合是机器学习中常见的问题之一,它指的是模型在训练集上表现良好,但在测试集或新数据上表现不佳的情况。过拟合的原因是模型过于复杂,过度拟合了训练集的噪声和细节,导致泛化能力下降。
解决方案 1. 数据集扩充:增加更多的训练样本可以减少过拟合的风险。通…

KL Divergence ——衡量两个概率分布之间的差异
文章目录1 什么是KL Divergence(KL散度,也说是KL距离)2 一个简单的例子3 KL的性质4 KL散度的公式介绍5 Pytorch实现KL散度——F.kl_div()5.1 函数原型5.2 简单代码6 KL散度在R- Drop中的应用6.1 什么是Dropout?6.2 引入 R-drop6.3 在R-Drop的…
【机器学习】从贝叶斯角度理解正则化缓解过拟合
从贝叶斯角度理解正则化缓解过拟合
参考: LR正则化与数据先验分布的关系? - Charles Xiao的回答 - 知乎
原始的Linear Regression
假设有若干数据 (x1,y1),(x2,y2),...,(xm,ym),我们要对其进行线性回归。也就是得到一个方程 yωTxϵ注意,…
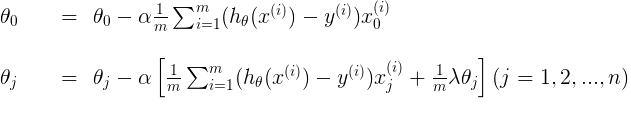
逻辑斯谛回归正则化 regularized logistic regression
逻辑斯谛回归正则化 regularized logistic regression 关于logistic回归的基础知识请参见我的前两篇博客:逻辑回归(代价函数,梯度下降) logistic regression--cost function and gradient descent 和 逻辑回归之决策边界 logisti…

LR的公式推导和过拟合问题解决方案
原文链接 Stanford机器学习课程笔记——LR的公式推导和过拟合问题解决方案 1. Logistic Regression 前面说的单变量线性回归模型和多变量线性回归模型,它们都是线性的回归模型。实际上,很多应用情况下,数据的模型不是一个简单的线性表示就可以…

深度学习解决过拟合——数据增广
Data Augmentation
前言:在现实生活中,带有标签的数据往往不好找到,因此我们对于数据量少的分类任务,使得在训练神经网络的过程中,常常会出现过拟合的现象。 因此数据增强对于解决过拟合问题是最重要的途径。
展示即…
机器学习和深度学习中,L2正则化为什么能防止过拟合?
正则化是为了降低模型的复杂度,模型过于复杂,则过拟合;
与傅里叶变换类似,高频的部分表示细节,尽量减少高频部分的影响;
傅里叶级数也是,高阶表示细节;
当阶数较高时,…

李宏毅机器学习——学习笔记(2)
Regression
每类特定的参数值构成一个特定的function,所有的参数可取值构成的集合,就是一个function set.loss function的输入是模型的一个特定function, 输出是loss值。
Gradient Descent 梯度下降的方法可以求解任意的loss function&…

【机器学习基础】正则化
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战 欢迎订阅&am…
机器学习之特征转换与过拟合(机器学习基石)
什么是特征转换
特征转换就是将原始资料(不容易数据化)转换为有意义的资料(能够数据化),或者说是计算机能够处理的资料。
比如说我们可以将像素点转换为一些有强度特制的,对称性的资料以便我们从中找出规律…